Python 装饰器机制详解:从原理到工程实践
一、核心概念与设计动机
在大型软件系统中,我们经常需要处理一些跨模块的通用功能,例如日志记录、权限验证、性能监控或事务管理。如果在每个业务逻辑函数中都手动添加这些代码,会导致严重的重复劳动,且一旦需求变更,维护成本极高。
为了解决这一问题,Python 引入了装饰器(Decorator)模式。这是一种基于"面向切面编程"(AOP)思想的实现方式,允许我们在不修改原始函数源代码和调用方式的前提下,动态地为对象增添新功能。
二、前置知识:高阶函数与闭包
理解装饰器的基石在于掌握两个 Python 特性:函数是一等公民,以及闭包的作用域规则。
1. 函数即对象
在 Python 中,函数名本质上是一个指向内存中函数对象的变量引用。这意味着函数可以像整数或字符串一样被赋值、传递和返回。
def say_hello():
print("Hello World")
# 将函数引用赋值给新变量
handler = say_hello
# 通过新变量调用原函数
handler()
print(say_hello is handler) # 输出 True2. 嵌套函数与闭包
当一个内部函数引用了外部作用域的变量时,该内部函数被称为闭包。即使外部函数执行结束,内部函数依然能记住并使用外部环境的状态。
def create_counter(initial_value):
count = initial_value
def increment():
nonlocal count
count += 1
return count
return increment
counter = create_counter(0)
print(counter()) # 输出 1
print(counter()) # 输出 2三、基础装饰器实现
最基础的装饰器就是一个接收函数参数并返回新函数的包装器。语法糖 @wrapper 本质上是等价于将该函数作为参数传给装饰器并重新赋值。
场景示例:我们需要统计一个数据查询函数的耗时。
import time
def performance_monitor(target_func):
def enhanced_wrapper(*args, **kwargs):
start_timestamp = time.time()
result = target_func(*args, **kwargs)
duration = time.time() - start_timestamp
print(f"[监控] {target_func.__name__} 耗时:{duration:.4f}s")
return result
return enhanced_wrapper
@performance_monitor
def fetch_user_data(user_id):
time.sleep(0.5) # 模拟耗时操作
return {"id": user_id, "status": "active"}
fetch_user_data(1001)在此结构中,fetch_user_data 实际上指向了 enhanced_wrapper。调用 fetch_user_data 时,先执行包裹逻辑,再执行真实业务。
四、进阶:带参数的装饰器
当装饰逻辑需要配置选项时(例如是否开启详细日志、设定超时阈值),普通的装饰器无法满足,需要构造三层嵌套结构:外层生成装饰器,中层是实际的装饰函数,内层是被包装的函数。
def logger_config(log_level='INFO'):
"""外层:接受配置参数"""
def decorator(func):
"""中层:接受被装饰的函数"""
def wrapper(*args, **kwargs):
print(f"[*{log_level}*] 执行开始")
result = func(*args, **kwargs)
print(f"[*{log_level}*] 执行结束")
return result
return wrapper
return decorator
@logger_config(log_level='DEBUG')
def calculate_sum(a, b):
return a + b
calculate_sum(10, 20)执行逻辑顺序如下:
1. 程序加载时执行 logger_config('DEBUG'),返回 decorator。
2. 使用返回的 decorator 装饰 calculate_sum,返回 wrapper。
3. 最终 calculate_sum 指向 wrapper。
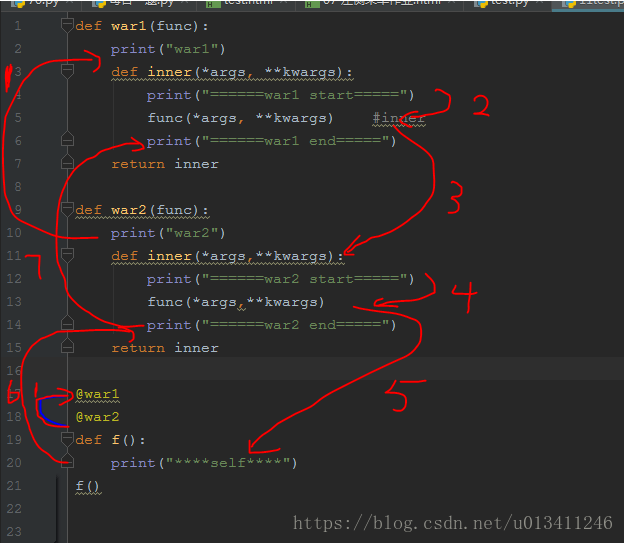
五、多重装饰器的执行栈
一个函数可以被多个装饰器叠加修饰。理解其执行顺序至关重要,通常遵循"洋葱模型"。
- 定义阶段:从内向外执行(离函数近的装饰器先运行)。
- 调用阶段:从外向内进入,再从内向出(类似入栈和出栈)。
def dec_A(func):
print("[定义 A]")
def inner():
print("[执行 A 前]")
func()
print("[执行 A 后]")
return inner
def dec_B(func):
print("[定义 B]")
def inner():
print("[执行 B 前]")
func()
print("[执行 B 后]")
return inner
@dec_A
@dec_B
def run_task():
print(">> 任务本体")
run_task()预期输出分析:
1. 定义阶段先打印 [定义 B] 后打印 [定义 A]。
2. 调用阶段先打印 [执行 A 前],接着 [执行 B 前],然后 >> 任务本体,返回后依次打印 [执行 B 后] 和 [执行 A 后]。
六、类装饰器方案
除了函数式装饰器,类也可以充当装饰器。只要该类实现了 __call__ 方法,其实例就可以被当作函数调用。类装饰器适合需要保存状态或更复杂管理的场景。
class PerformanceTracker:
def __init__(self, func):
self.func = func
self.call_count = 0
def __call__(self, *args, **kwargs):
self.call_count += 1
print(f"第 {self.call_count} 次调用 {self.func.__name__}")
return self.func(*args, **kwargs)
@PerformanceTracker
def send_notification(msg):
print(f"发送消息:{msg}")
send_notification("你好")
send_notification("再见")七、元信息保护:functools.wraps
使用装饰器后,原函数的名称(__name__)和文档串(__doc__)会被包装器覆盖。为了调试和文档生成的准确性,应使用标准库中的 functools.wraps。
from functools import wraps
def audit_log(func):
@wraps(func) # 复制原函数属性
def wrapper(*args, **kwargs):
print(f"审计日志触发:{func.__name__}")
return func(*args, **kwargs)
return wrapper
@audit_log
def delete_record(id):
"""删除指定 ID 的记录"""
pass
print(delete_record.__name__) # 输出 delete_record
print(delete_record.__doc__) # 输出 删除指定 ID 的记录八、常见误区排查
Q1: 为什么装饰器里忘记返回函数会报错?
装饰器的返回值必须是一个可调用对象。如果内部只执行了逻辑但未 return 新的函数对象,原函数名将指向 None,导致后续调用崩溃。
Q2: 为什么要用 *args 和 **kwargs?
为了保证装饰器具有通用性,无论被装饰函数原本接收几个参数、什么类型的参数,包装器都能正确透传,避免硬编码参数数量。
# 正确的通用写法
def universal_wrapper(func):
def inner(*args, **kwargs):
return func(*args, **kwargs)
return inner