Python实现《王者荣耀》交易数据抓取与多维度可视化分析
引言
《王者荣耀》作为一款广受欢迎的移动游戏,其账号交易市场日益活跃。为了深入了解这一市场的动态和趋势,本项目旨在通过数据采集技术获取相关交易数据,并利用数据可视化方法进行多维度分析。这不仅有助于玩家和商家了解市场行情,做出更明智的决策,也是对爬虫技术、数据清洗以及数据可视化等技能的一次综合实践。
环境配置
为顺利执行本项目,需要安装以下Python库:
requests: 负责发送HTTP请求,获取网页内容。csv: 用于将抓取到的结构化数据保存为CSV文件格式。execjs: 能够执行JavaScript代码,用于处理网页中涉及的加密逻辑。json: 处理JSON格式的数据,解析API响应。random和time: 控制请求间隔,模拟用户行为,避免触发反爬机制。
您可以通过以下命令安装所需库:
pip install requests execjs pandas matplotlib seaborn
数据字段概览
本项目旨在从交易平台收集以下关键字段,以便对《王者荣耀》账号市场进行全面分析:
| 字段名 | 描述 |
|---|---|
| 商品标题 | 交易商品的文字描述,通常包含账号的核心卖点。 |
| 所属区服 | 账号所在的游戏服务器分区信息。 |
| 游戏名称 | 明确交易的游戏名称,此处为"王者荣耀"。 |
| 商品分类 | 账号的交易类型,例如"账号"、"皮肤"等。 |
| 当前价格 | 商品的实际销售价格。 |
| 初始价格 | 商品的原定价格,可能与当前价格有折扣。 |
| 账号亮点 | 突出账号价值的特色描述,如稀有皮肤、高贵族等级等。 |
| 服务保障 | 交易平台提供的额外服务,例如"放心购"、"花呗分期"等。 |
| 浏览量 | 商品的页面访问次数,反映关注度。 |
| 热度值 | 综合评价商品受欢迎程度的指标。 |
| 上架时间 | 商品首次在平台发布的时间。 |
| 详情链接 | 指向商品详细页面的URL。 |
爬取流程解析
1. 目标网站分析
在开始数据抓取前,需利用浏览器开发者工具(如Chrome DevTools)对目标网站进行详细分析。我们发现,交易数据通常通过POST请求异步加载,且请求头和请求体中包含了一系列加密参数,例如时间戳(Timestamp)、随机字符串(Random)和签名(Sign)。这些参数是确保请求合法性的关键。
2. 加密参数逆向工程
识别出加密参数后,下一步是逆向分析其生成逻辑。通过检查网站的JavaScript文件,可以定位到负责生成这些加密参数的函数。本项目中,我们使用execjs库加载并执行这些JavaScript代码,以动态生成合法的请求头和请求体数据。这是成功获取受保护数据的核心步骤。
3. 发送请求与响应处理
构建好带有正确加密参数的请求头和请求体后,使用requests库向目标API接口发送POST请求。成功获取响应后,利用json库解析返回的JSON数据。随后,我们将提取出的关键数据组织成字典格式,为后续的数据存储做准备。
# 假设已解析得到以下数据
item_data = {
'product_title': parsed_title,
'game_server_region': parsed_server,
'game_name': parsed_game_name,
'product_category': parsed_category,
'current_price_yuan': parsed_price,
'original_price_yuan': parsed_original_price,
'selling_points': parsed_highlights,
'service_features': parsed_services,
'view_counts': parsed_views,
'popularity_score': parsed_hotness,
'listed_time': parsed_publish_time,
'detail_url': parsed_detail_url,
}
print(item_data)
# 将 item_data 写入CSV文件
# csv_writer.writerow(item_data.values())
4. 数据持久化
为了便于后续分析,采集到的数据将被保存为CSV格式文件。在数据保存时,需确保字段与表头准确对应,并尽可能保持数据的完整性。

5. 请求频率控制
为了避免被目标网站识别为爬虫并进行封禁,控制请求频率至关重要。我们通过在每次请求之间引入随机延迟来模拟人类用户的浏览行为。例如,每次请求后暂停1到3秒:
import time
import random
time.sleep(random.uniform(1, 3))
6. 异常处理与重试机制
网络请求可能因多种因素失败,如网络中断、服务器过载或请求超时。为了提升爬虫的鲁棒性,需要实现异常处理和重试机制。以下是一个包含重试逻辑的请求函数示例:
import requests
def fetch_page_data(target_url, headers_dict, data_payload, max_retries=3):
"""
尝试从指定URL获取数据,包含重试机制。
:param target_url: 目标API的URL。
:param headers_dict: 请求头字典。
:param data_payload: 请求体数据。
:param max_retries: 最大重试次数。
:return: 成功时的JSON响应数据,或失败时返回None。
"""
attempt_count = 0
while attempt_count < max_retries:
try:
response = requests.post(target_url, headers=headers_dict, data=data_payload, timeout=10)
response.raise_for_status() # 检查HTTP错误
return response.json()
except requests.exceptions.RequestException as e:
print(f"请求 {target_url} 时发生错误 (尝试 {attempt_count + 1}/{max_retries}): {e}")
attempt_count += 1
time.sleep(2 * attempt_count) # 每次重试增加等待时间
print(f"请求 {target_url} 最终失败,跳过该操作。")
return None
# 示例调用
# api_url = "http://example.com/api/data"
# headers = {"Content-Type": "application/json", "Sign": "generated_sign", ...}
# payload = {"page": 1, "size": 20}
# page_content = fetch_page_data(api_url, headers, json.dumps(payload))
# if page_content:
# print("成功获取数据:", page_content)
数据可视化呈现
通过对采集到的十余万条数据进行处理,我们进行了一系列可视化分析,以揭示《王者荣耀》账号交易市场的深层规律。以下是部分可视化图表及其对应的生成代码。
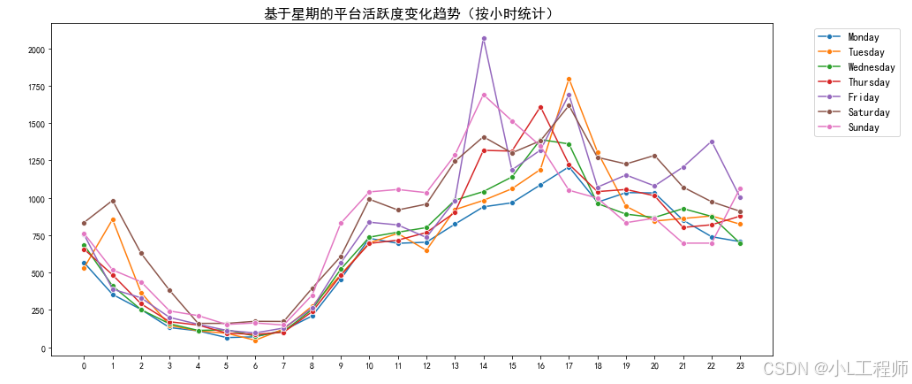
1. 基于星期的平台活跃度变化趋势(按小时统计)
该图表展示了平台在不同星期和小时的活跃程度,有助于发现交易高峰时段。
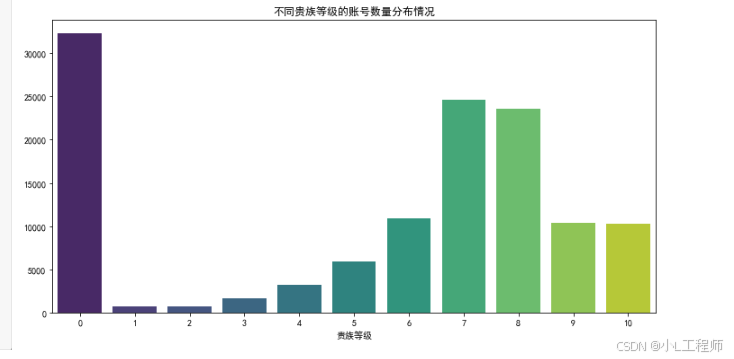
2. 不同贵族等级的账号数量分布情况
此图表分析了不同贵族等级(VIP等级)账号在交易市场中的数量分布,反映了不同等级账号的供需状况。
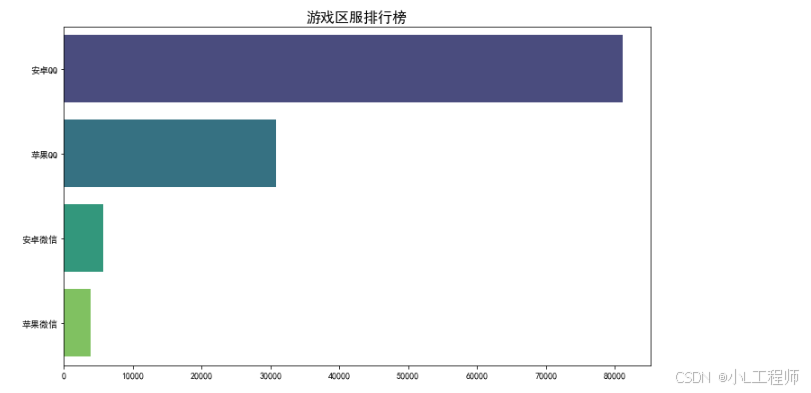
3. 游戏区服热度排行榜
本图展示了不同游戏区服的交易量或关注度排名,揭示了哪些区服的账号更受欢迎。
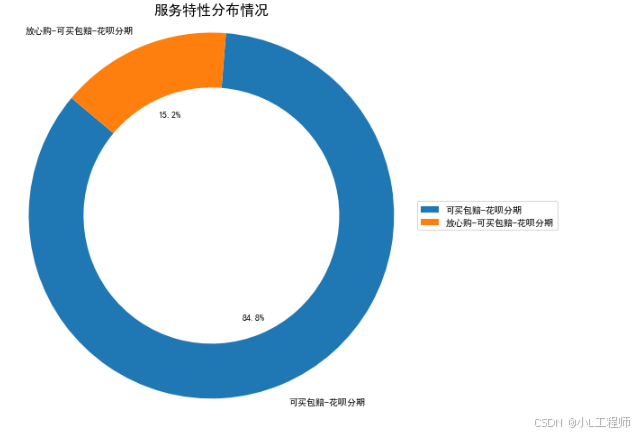
4. 服务特性分布情况
饼图展示了各类服务特性(如"放心购"、"可买包赔"等)在所有交易中的比例,反映了买家对哪些服务更为看重。
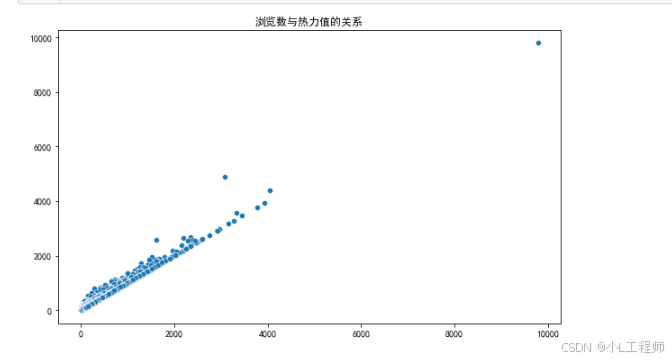
5. 浏览量与热度值的关系
散点图描绘了商品的浏览量与热度值之间的关系,用于探索二者是否存在关联性以及关联强度。
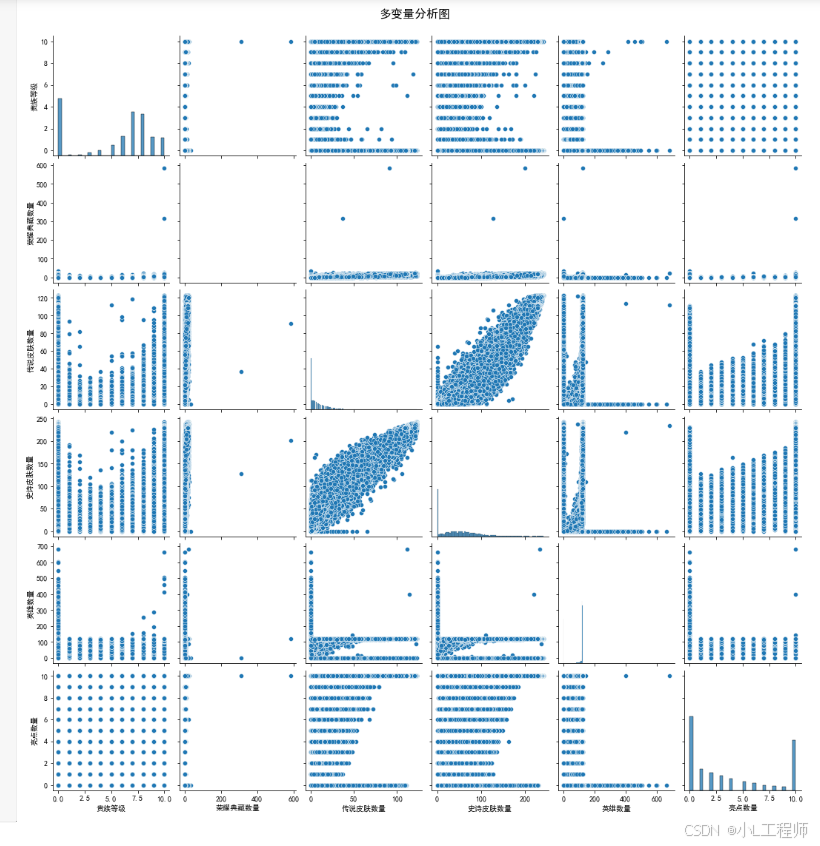
6. 多变量分析图
该图通过多变量散点矩阵,展示了多个数值型变量(如贵族等级、皮肤数量等)之间的两两关系。
主要可视化代码
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 为了中文显示正常,需要配置matplotlib
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
# 假设 game_data_df 已经加载并包含所有数据
# 例如:game_data_df = pd.read_csv('honor_of_kings_trades.csv')
# 确保 'listed_time' 列是日期时间类型
# game_data_df['listed_time'] = pd.to_datetime(game_data_df['listed_time'])
# game_data_df['hour_of_day'] = game_data_df['listed_time'].dt.hour
# game_data_df['day_of_week'] = game_data_df['listed_time'].dt.day_name() # 或 dt.weekday
# 1. 基于星期的平台活跃度变化趋势(按小时统计)
# 假设数据框中已有 'hour_of_day' 和 'day_of_week' 列
daily_hourly_activity = game_data_df.groupby(['hour_of_day', 'day_of_week']).size().reset_index(name='activity_count')
weekday_order = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
daily_hourly_activity['day_of_week'] = pd.Categorical(daily_hourly_activity['day_of_week'], categories=weekday_order, ordered=True)
daily_hourly_activity = daily_hourly_activity.sort_values(['hour_of_day', 'day_of_week'])
plt.figure(figsize=(14, 6))
sns.lineplot(data=daily_hourly_activity, x='hour_of_day', y='activity_count', hue='day_of_week', marker='o')
plt.title('基于星期的平台活跃度变化趋势(按小时统计)', fontsize=16)
plt.xlabel('小时')
plt.ylabel('交易数量')
plt.xticks(range(24))
plt.legend(title='星期', bbox_to_anchor=(1.05, 1), loc='upper left', fontsize=12)
plt.tight_layout()
plt.show()
# 2. 不同贵族等级的账号数量分布情况
# 假设数据框中已有 'vip_level' 列
plt.figure(figsize=(12, 6))
sns.countplot(x='vip_level', data=game_data_df, palette='viridis')
plt.title('不同贵族等级的账号数量分布情况')
plt.xlabel('贵族等级')
plt.ylabel('账号数量')
plt.show()
# 3. 游戏区服排行榜
# 假设数据框中已有 'game_server_region' 列
top_servers = game_data_df['game_server_region'].value_counts().nlargest(10) # 取前10个
plt.figure(figsize=(10, 6))
sns.barplot(x=top_servers.values, y=top_servers.index, palette='viridis')
plt.title('游戏区服热度排行榜', fontsize=16)
plt.xlabel('交易数量')
plt.ylabel('游戏区服')
plt.tight_layout()
plt.show()
# 4. 服务特性分布情况
# 假设数据框中已有 'service_features' 列
service_counts = game_data_df['service_features'].value_counts()
plt.figure(figsize=(8, 8))
plt.pie(service_counts, labels=service_counts.index, autopct='%1.1f%%', startangle=140, wedgeprops=dict(width=0.3))
plt.title('服务特性分布情况', fontsize=16)
plt.legend(service_counts.index, title='服务类型', loc='center left', bbox_to_anchor=(1, 0, 0.5, 1))
plt.axis('equal')
plt.show()
# 5. 浏览量与热度值的关系
# 假设数据框中已有 'view_counts' 和 'popularity_score' 列
plt.figure(figsize=(10, 6))
sns.scatterplot(x='view_counts', y='popularity_score', data=game_data_df, palette='viridis')
plt.title('浏览量与热度值的关系')
plt.xlabel('浏览量')
plt.ylabel('热度值')
plt.show()
# 6. 多变量分析图
# 假设数据框中已有以下数值列
numerical_features = ['vip_level', 'legendary_skin_count', 'epic_skin_count', 'hero_count', 'highlight_count']
# 确保这些列存在且是数值类型,如果不存在或名称不同,需要根据实际数据调整
# 例如:game_data_df['legendary_skin_count'] = game_data_df['legendary_skin_count'].fillna(0)
# game_data_df['epic_skin_count'] = game_data_df['epic_skin_count'].fillna(0)
# game_data_df['hero_count'] = game_data_df['hero_count'].fillna(0)
# game_data_df['highlight_count'] = game_data_df['selling_points'].apply(lambda x: len(x.split(',')) if isinstance(x, str) else 0)
game_data_numerical = game_data_df[numerical_features]
sns.pairplot(game_data_numerical)
plt.suptitle('多变量分析图', y=1.02, fontsize=16)
plt.show()
