优先级队列及其底层堆结构的原理与实现
优先级队列的概念
在常规队列中,数据遵循先进先出(FIFO)的原则。然而,在许多实际场景中,我们需要根据元素的优先级来决定出队顺序,例如操作系统的任务调度或游戏中的事件处理。优先级队列(Priority Queue)正是为了解决这类问题而设计的数据结构,它保证每次从队列中取出的都是优先级最高的元素。
堆(Heap)的结构与性质
Java 中的 PriorityQueue 底层通常采用"堆"这种数据结构。堆在逻辑上是一棵完全二叉树,而在物理上通过一维数组进行顺序存储。
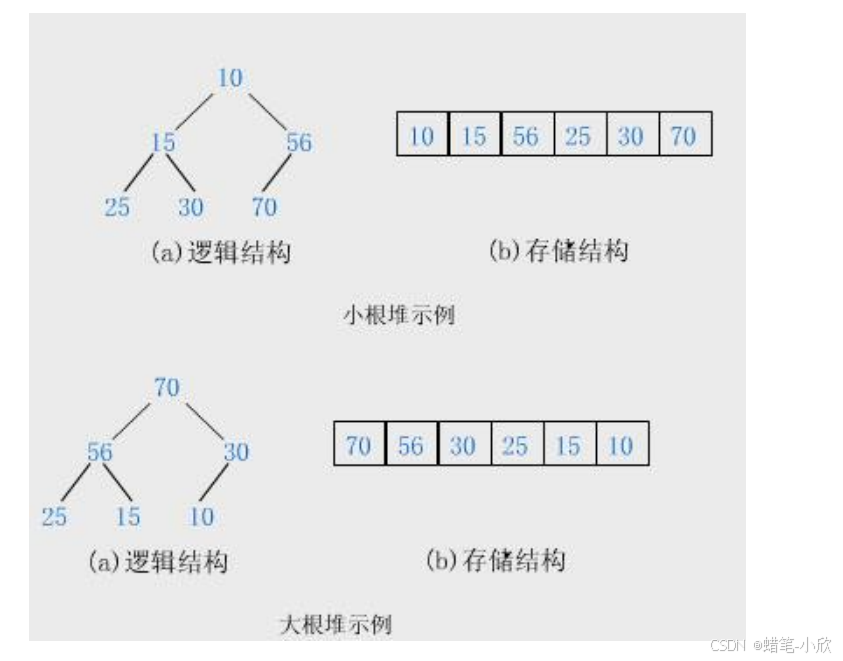
- 大根堆(Max Heap): 树中任意节点的值均不小于其左右孩子节点的值。根节点是整个堆中的最大值。
- 小根堆(Min Heap): 树中任意节点的值均不大于其左右孩子节点的值。根节点是整个堆中的最小值。
堆的存储与索引规律
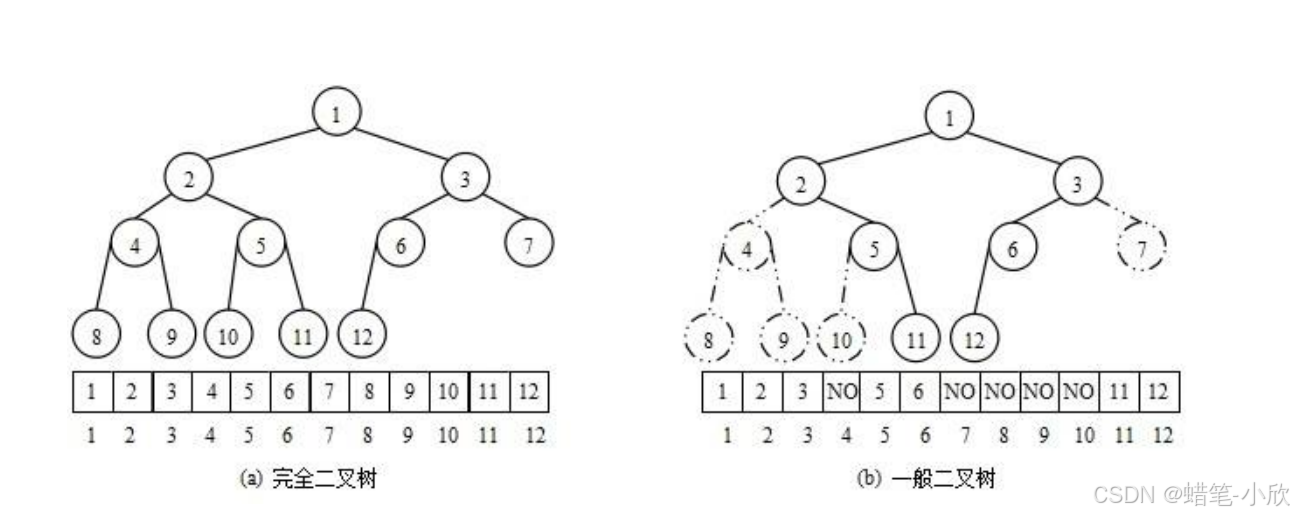
由于堆是一棵完全二叉树,使用数组存储可以极大提高空间利用率。假设节点在数组中的索引为 i,则其关联节点的索引计算公式如下:
- 父节点索引:
(i - 1) / 2(当 i > 0 时)。 - 左孩子索引:
2 * i + 1。 - 右孩子索引:
2 * i + 2。
堆的模拟实现
下面我们将通过代码实现一个大根堆的核心逻辑,包括建堆、向下调整和向上调整。
import java.util.Arrays;
public class CustomHeap {
private int[] dataStore;
private int currentSize;
public CustomHeap(int capacity) {
this.dataStore = new int[capacity];
}
public void loadData(int[] source) {
for (int i = 0; i < source.length; i++) {
dataStore[i] = source[i];
currentSize++;
}
}
// 构建大根堆
public void buildMaxHeap() {
// 从最后一个非叶子节点开始向上遍历进行向下调整
for (int p = (currentSize - 1 - 1) / 2; p >= 0; p--) {
adjustDown(p, currentSize);
}
}
// 向下调整算法
public void adjustDown(int rootIndex, int limit) {
int targetChild = 2 * rootIndex + 1;
while (targetChild < limit) {
// 选取左右孩子中较大的一个
if (targetChild + 1 < limit && dataStore[targetChild] < dataStore[targetChild + 1]) {
targetChild++;
}
// 如果孩子节点大于根节点,则交换
if (dataStore[targetChild] > dataStore[rootIndex]) {
swapElements(targetChild, rootIndex);
rootIndex = targetChild;
targetChild = 2 * rootIndex + 1;
} else {
break;
}
}
}
private void swapElements(int a, int b) {
int temp = dataStore[a];
dataStore[a] = dataStore[b];
dataStore[b] = temp;
}
}
元素的插入与删除
1. 元素插入(入队)
插入操作首先将新元素放在数组末尾,然后通过"向上调整"使其回到正确位置。向上调整的时间复杂度为 O(log N)。
public void push(int val) {
if (currentSize == dataStore.length) {
dataStore = Arrays.copyOf(dataStore, dataStore.length * 2);
}
dataStore[currentSize++] = val;
adjustUp(currentSize - 1);
}
public void adjustUp(int childIdx) {
int parentIdx = (childIdx - 1) / 2;
while (parentIdx >= 0) {
if (dataStore[childIdx] > dataStore[parentIdx]) {
swapElements(childIdx, parentIdx);
childIdx = parentIdx;
parentIdx = (childIdx - 1) / 2;
} else {
break;
}
}
}
2. 元素删除(出队)
通常删除的是堆顶元素。步骤是将堆顶元素与数组最后一个元素交换,减小有效长度,再对堆顶进行一次向下调整。
public int pop() {
if (currentSize == 0) return -1;
int topValue = dataStore[0];
swapElements(0, currentSize - 1);
currentSize--;
adjustDown(0, currentSize);
return topValue;
}
Java PriorityQueue 接口详解
Java 标准库中的 PriorityQueue 实现了 Queue 接口。使用时需注意:
- 默认排序: 默认情况下实现的是小根堆。
- 非线程安全: 若需在多线程环境下使用,请考虑
PriorityBlockingQueue。 - 约束: 不能插入
null,且插入的元素必须是可比较的(实现Comparable或提供Comparator)。
常用操作示例
import java.util.PriorityQueue;
import java.util.Collections;
public class PriorityDemo {
public static void main(String[] args) {
// 默认小根堆
PriorityQueue<Integer> minHeap = new PriorityQueue<>();
// 使用比较器构建大根堆
PriorityQueue<Integer> maxHeap = new PriorityQueue<>(Collections.reverseOrder());
maxHeap.offer(15);
maxHeap.offer(40);
maxHeap.offer(10);
System.out.println(maxHeap.peek()); // 获取最大值: 40
System.out.println(maxHeap.poll()); // 移除并返回最大值: 40
}
}
经典应用:Top-K 问题
在海量数据中寻找最小的 K 个数,可以使用堆来优化。如果要求最小的 K 个数,可以建立一个容量为 K 的大根堆:
- 取前 K 个元素建立大根堆。
- 遍历后续元素,若当前元素小于堆顶,则替换堆顶并重新调整堆。
- 遍历结束,堆中即为最小的 K 个数。
public int[] getSmallestK(int[] input, int k) {
if (k <= 0) return new int[0];
// 使用默认小根堆找到前K个最小值
PriorityQueue<Integer> pQueue = new PriorityQueue<>();
for (int num : input) {
pQueue.offer(num);
}
int[] result = new int[k];
for (int i = 0; i < k; i++) {
result[i] = pQueue.poll();
}
return result;
}
堆排序(Heap Sort)
堆排序是利用堆思想的一种高效排序算法。 升序排列: 建立大根堆,不断将堆顶(最大值)与末尾元素交换并缩小堆范围进行调整。 降序排列: 建立小根堆,同理操作。 建堆的时间复杂度为 O(N),排序过程通过 N 次调整,总时间复杂度为 O(N log N),且为原地排序,空间复杂度为 O(1)。
