树链剖分详解与应用
基本概念
树链剖分是一种将树形结构转化为链式结构的技术,能够高效处理树上路径和子树相关操作。
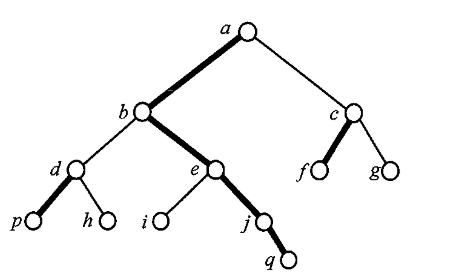
核心定义包括:
- 重儿子:对于非叶节点,子树规模最大的子节点
- 轻儿子:除重儿子外的所有子节点
- 重边:连接重儿子与其父节点的边
- 重链:由连续重边构成的路径
- 轻边:非重边的边
- 链头:重链中深度最小的节点
工作原理
树链剖分的关键性质:任意节点到根节点的路径上,经过的重链数量和轻边数量都不超过 O(log n)。
这一性质的证明基于二叉树模型:跨越轻边时,子树规模至少减半,因此最多经过 log n 条轻边。
LCA计算优化
利用树链剖分求最近公共祖先:
- 当两节点不在同一重链时,深度较大的链头向上跳跃
- 当两节点位于同一重链时,深度较小的即为LCA
#include <bits/stdc++.h>
#define int long long
using namespace std;
const int N = 1e6 + 10;
int depth[N], chainHead[N], parent[N], subtreeSize[N], heavySon[N];
vector<int> tree[N];
void computeSubtree(int node) {
subtreeSize[node] = 1;
depth[node] = depth[parent[node]] + 1;
for (int child : tree[node]) {
if (child == parent[node]) continue;
parent[child] = node;
computeSubtree(child);
subtreeSize[node] += subtreeSize[child];
if (subtreeSize[child] > subtreeSize[heavySon[node]]) {
heavySon[node] = child;
}
}
}
void assignChain(int node, int head) {
chainHead[node] = head;
if (heavySon[node]) {
assignChain(heavySon[node], head);
}
for (int child : tree[node]) {
if (child == parent[node] || child == heavySon[node]) continue;
assignChain(child, child);
}
}
int findLCA(int a, int b) {
while (chainHead[a] != chainHead[b]) {
if (depth[chainHead[a]] > depth[chainHead[b]]) {
a = parent[chainHead[a]];
} else {
b = parent[chainHead[b]];
}
}
return depth[a] < depth[b] ? a : b;
}
signed main() {
ios::sync_with_stdio(false);
cin.tie(0); cout.tie(0);
int nodes, queries, root;
cin >> nodes >> queries >> root;
for (int i = 1; i < nodes; i++) {
int u, v;
cin >> u >> v;
tree[u].push_back(v);
tree[v].push_back(u);
}
computeSubtree(root);
assignChain(root, root);
while (queries--) {
int a, b;
cin >> a >> b;
cout << findLCA(a, b) << '\n';
}
return 0;
}
高级应用:路径与子树操作
树链剖分结合线段树可高效处理以下操作:
- 路径节点值修改与查询
- 子树节点值修改与查询
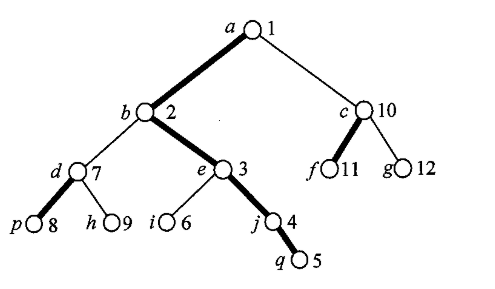
关键在于DFS序的连续性:重链节点在线段树中位置连续,子树节点同样连续。
#include <bits/stdc++.h>
#define int long long
#define LEFT (index << 1)
#define RIGHT (index << 1 | 1)
using namespace std;
const int MAXN = 1e6 + 10;
int MOD, nodeCount, operationCount, root, timestamp;
int initialValues[MAXN], mappedValues[MAXN], position[MAXN];
int size[MAXN], level[MAXN], heavyChild[MAXN], father[MAXN], chainTop[MAXN];
vector<int> adj[MAXN];
struct SegmentNode {
int left, right, value, sum, lazy;
} segTree[MAXN];
void updateUp(int index) {
segTree[index].sum = (segTree[LEFT].sum + segTree[RIGHT].sum) % MOD;
}
void propagateDown(int index) {
if (segTree[index].lazy) {
segTree[LEFT].sum = (segTree[LEFT].sum + (segTree[LEFT].right - segTree[LEFT].left + 1) * segTree[index].lazy % MOD) % MOD;
segTree[RIGHT].sum = (segTree[RIGHT].sum + (segTree[RIGHT].right - segTree[RIGHT].left + 1) * segTree[index].lazy % MOD) % MOD;
segTree[LEFT].lazy = (segTree[LEFT].lazy + segTree[index].lazy) % MOD;
segTree[RIGHT].lazy = (segTree[RIGHT].lazy + segTree[index].lazy) % MOD;
segTree[index].lazy = 0;
}
}
void buildTree(int index, int l, int r) {
segTree[index] = {l, r, 0, 0, 0};
if (l == r) {
segTree[index].sum = mappedValues[l];
return;
}
int mid = (l + r) >> 1;
buildTree(LEFT, l, mid);
buildTree(RIGHT, mid + 1, r);
updateUp(index);
}
void rangeAdd(int index, int l, int r, int delta) {
if (segTree[index].left >= l && segTree[index].right <= r) {
segTree[index].sum = (segTree[index].sum + (segTree[index].right - segTree[index].left + 1) * delta % MOD) % MOD;
segTree[index].lazy = (segTree[index].lazy + delta) % MOD;
return;
}
propagateDown(index);
int mid = (segTree[index].left + segTree[index].right) >> 1;
if (l <= mid) rangeAdd(LEFT, l, r, delta);
if (r > mid) rangeAdd(RIGHT, l, r, delta);
updateUp(index);
}
int rangeQuery(int index, int l, int r) {
if (segTree[index].left >= l && segTree[index].right <= r) {
return segTree[index].sum;
}
propagateDown(index);
int mid = (segTree[index].left + segTree[index].right) >> 1;
int result = 0;
if (l <= mid) result = (result + rangeQuery(LEFT, l, r)) % MOD;
if (r > mid) result = (result + rangeQuery(RIGHT, l, r)) % MOD;
return result;
}
void firstDFS(int node) {
size[node] = 1;
level[node] = level[father[node]] + 1;
for (int child : adj[node]) {
if (child == father[node]) continue;
father[child] = node;
firstDFS(child);
size[node] += size[child];
if (size[child] > size[heavyChild[node]]) {
heavyChild[node] = child;
}
}
}
void secondDFS(int node, int chainStart) {
chainTop[node] = chainStart;
position[node] = ++timestamp;
mappedValues[timestamp] = initialValues[node];
if (heavyChild[node]) {
secondDFS(heavyChild[node], chainStart);
}
for (int child : adj[node]) {
if (child == father[node] || child == heavyChild[node]) continue;
secondDFS(child, child);
}
}
void pathUpdate(int x, int y, int value) {
while (chainTop[x] != chainTop[y]) {
if (level[chainTop[x]] < level[chainTop[y]]) swap(x, y);
rangeAdd(1, position[chainTop[x]], position[x], value);
x = father[chainTop[x]];
}
if (level[x] > level[y]) swap(x, y);
rangeAdd(1, position[x], position[y], value);
}
int pathQuery(int x, int y) {
int result = 0;
while (chainTop[x] != chainTop[y]) {
if (level[chainTop[x]] < level[chainTop[y]]) swap(x, y);
result = (result + rangeQuery(1, position[chainTop[x]], position[x])) % MOD;
x = father[chainTop[x]];
}
if (level[x] > level[y]) swap(x, y);
result = (result + rangeQuery(1, position[x], position[y])) % MOD;
return result;
}
signed main() {
ios::sync_with_stdio(false);
cin.tie(0); cout.tie(0);
cin >> nodeCount >> operationCount >> root >> MOD;
for (int i = 1; i <= nodeCount; i++) cin >> initialValues[i];
for (int i = 1; i < nodeCount; i++) {
int u, v;
cin >> u >> v;
adj[u].push_back(v);
adj[v].push_back(u);
}
firstDFS(root);
secondDFS(root, root);
buildTree(1, 1, nodeCount);
while (operationCount--) {
int type, x, y, z;
cin >> type >> x;
switch (type) {
case 1:
cin >> y >> z;
pathUpdate(x, y, z);
break;
case 2:
cin >> y;
cout << pathQuery(x, y) << '\n';
break;
case 3:
cin >> z;
rangeAdd(1, position[x], position[x] + size[x] - 1, z);
break;
case 4:
cout << rangeQuery(1, position[x], position[x] + size[x] - 1) << '\n';
break;
}
}
return 0;
}
