Dify代码节点高级应用:提升工作流性能的实战指南
Dify代码节点高级应用:提升工作流性能的实战指南
还在为Dify工作流中的数据处理效率低下而烦恼?想通过代码节点实现复杂业务逻辑却不知从何下手?本文将为你提供从基础配置到高级应用的完整解决方案,帮助你充分发挥代码节点的潜力。
为什么Dify工作流需要代码节点?
Dify工作流中的代码节点是连接AI能力与现实业务需求的关键桥梁。与内置节点相比,代码节点提供了无与伦比的灵活性——你可以用Python代码实现任意复杂度的逻辑处理,调用丰富的第三方库,并与工作流中的其他节点无缝集成。
想象一下:你有一个CSV文件需要分析,传统方式可能需要导出到Excel、手动处理再导入。但在Dify中,一个简单的代码节点就能完成数据清洗、分析和可视化,整个过程自动化完成。
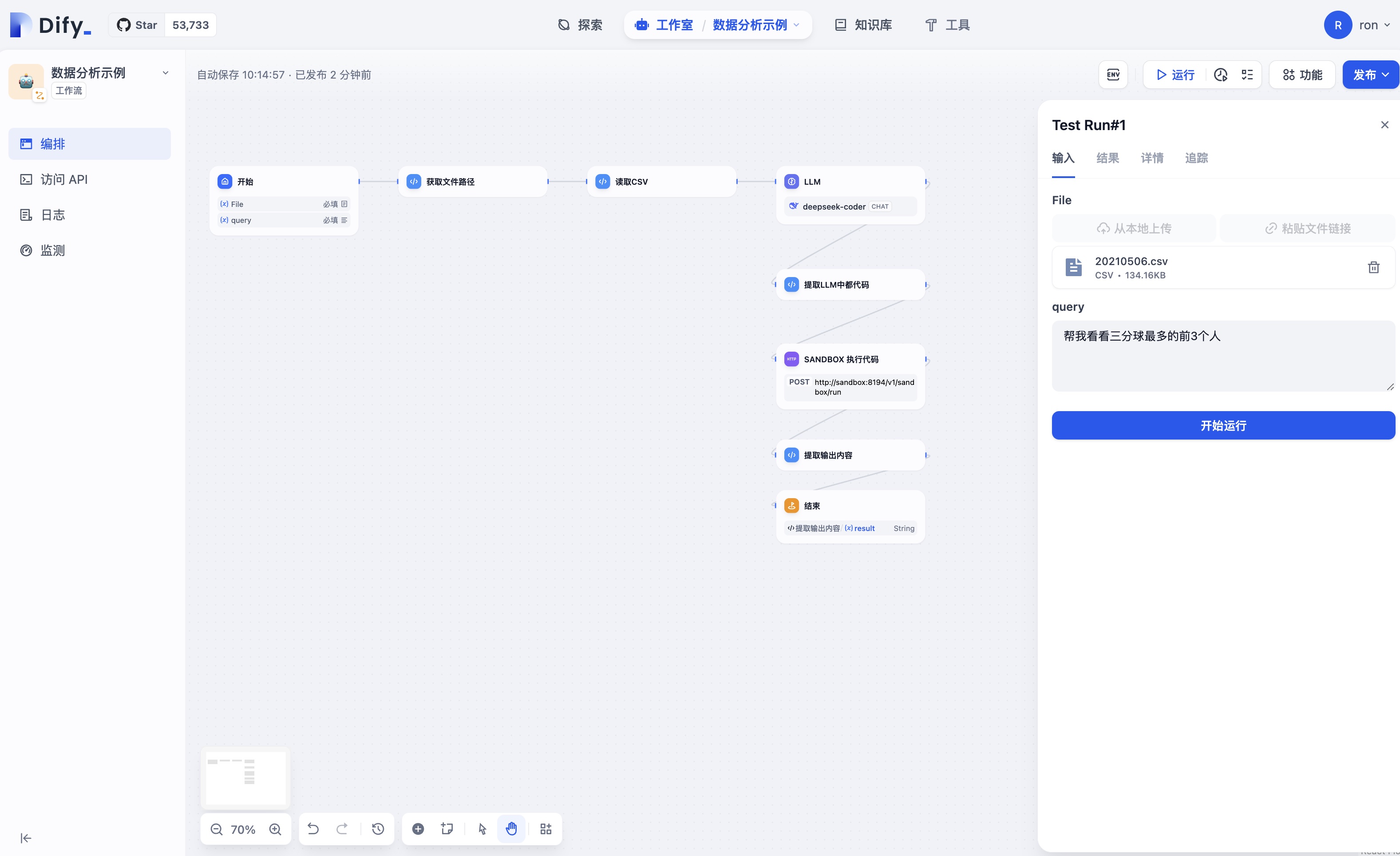
实战技巧1:解决文件路径访问难题
在Dify中处理用户上传文件时,最大的挑战是如何获取文件的实际路径。以下代码展示了如何通过文件大小匹配最新上传的文件,绕过Dify上传文件路径不直接可见的限制:
import os
import time
def locate_user_file(file_size):
matched_files = []
upload_directory = '/uploaded_data'
if not os.path.exists(upload_directory):
return {"file_location": "未找到文件"}
for root, directories, files in os.walk(upload_directory):
for file_name in files:
file_path = os.path.join(root, file_name)
file_info = os.stat(file_path)
if file_info.st_size == file_size:
matched_files.append((file_path, file_info.st_mtime))
if matched_files:
latest_file = max(matched_files, key=lambda x: x[1])
return {"file_location": str(latest_file[0])}
else:
return {"file_location": "未找到匹配文件"}
配合pandas库,你可以轻松读取CSV、Excel等多种格式的数据文件。
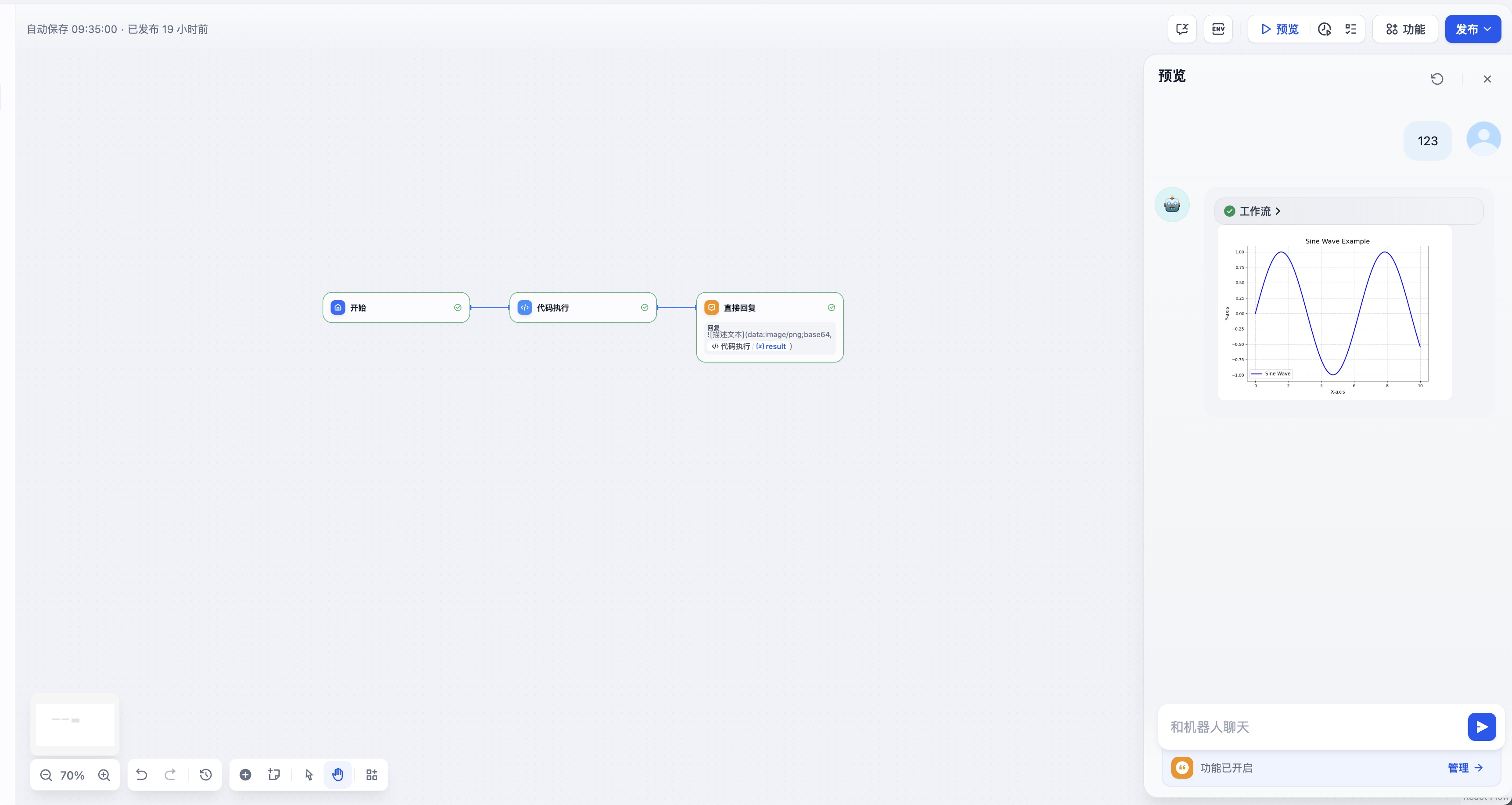
实战技巧2:数据可视化一键生成
数据只有可视化后才真正有价值。以下代码展示了如何在Dify中生成专业图表:
import matplotlib.pyplot as plt
import base64
from io import BytesIO
# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
def create_visualization(input_data):
plt.figure(figsize=(10, 6))
plt.plot(input_data['x_axis'], input_data['y_axis'])
plt.title('数据趋势分析')
# 转换为base64格式
image_buffer = BytesIO()
plt.savefig(image_buffer, format='png')
image_buffer.seek(0)
encoded_image = base64.b64encode(image_buffer.getvalue()).decode()
return {"chart": encoded_image}
实战技巧3:JSON数据智能修复
LLM生成的JSON经常格式不规范,导致后续处理失败。以下代码提供了强大的修复能力:
import json
import re
def correct_json_format(text):
"""修复不规范的JSON字符串"""
# 移除多余的引号和转义字符
text = re.sub(r'\\"', '"', text)
# 处理未闭合的括号
text = re.sub(r'\{[^{}]*$', '{', text)
text = re.sub(r'[^{]*\}$', '}', text)
# 处理未闭合的数组
text = re.sub(r'\[[^\]]*$', '[', text)
text = re.sub(r'[^\[]*\]$', ']', text)
return text
def process_json(json_text):
try:
parsed_data = json.loads(json_text)
return {"corrected_json": json.dumps(parsed_data, ensure_ascii=False, indent=2)}
except json.JSONDecodeError:
repaired = correct_json_format(json_text)
return {"corrected_json": repaired}
这个技巧特别适合处理API返回的JSON数据,确保数据格式的一致性。
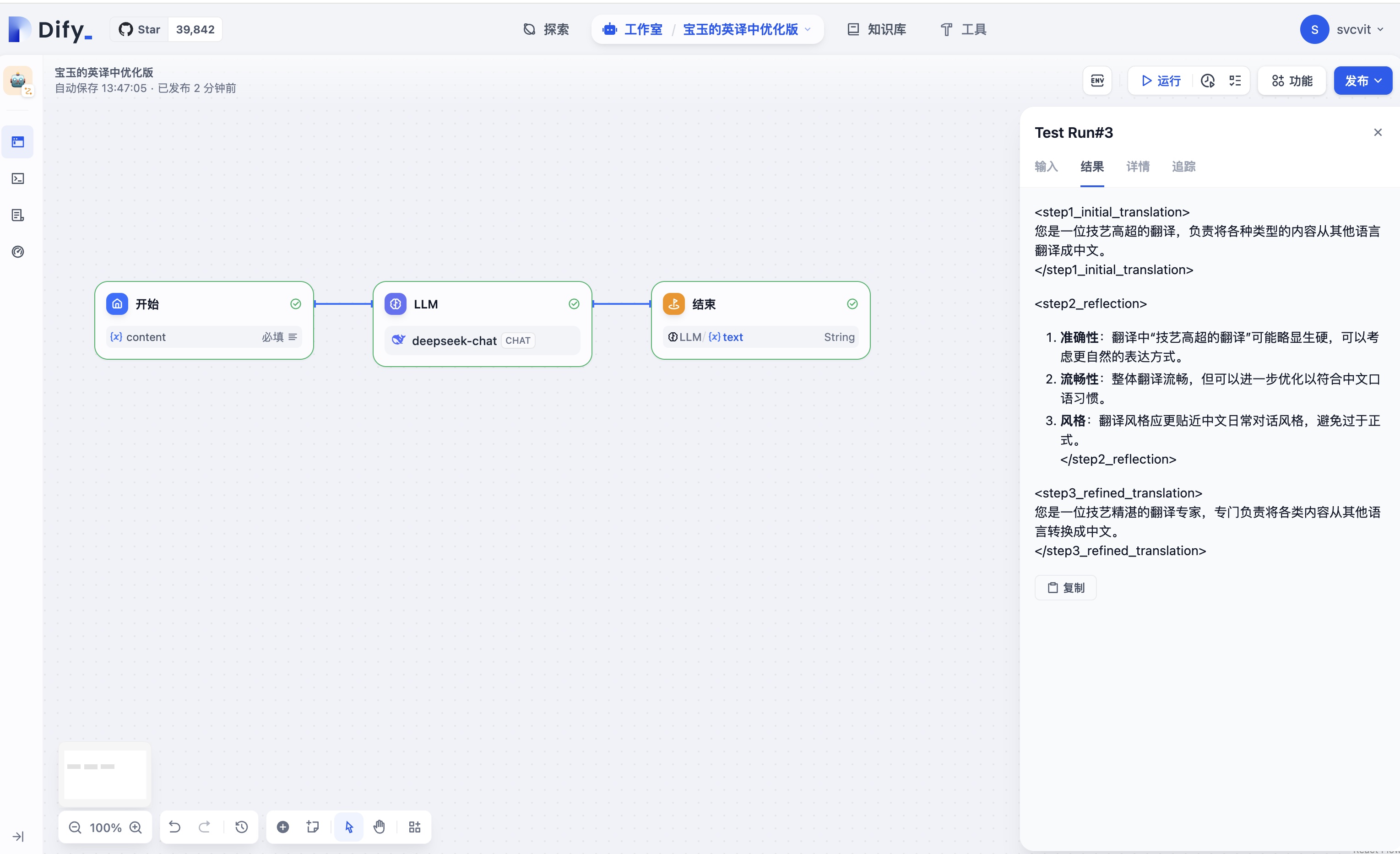
实战技巧4:多语言内容翻译优化
以下代码展示了如何通过代码节点实现专业级翻译:
def enhance_translation(original_text, translated_text):
"""优化翻译质量,保持专业术语一致性"""
# 术语表映射
terminology_map = {
"API": "应用程序接口",
"LLM": "大语言模型",
"workflow": "工作流",
"database": "数据库",
"algorithm": "算法"
}
for eng_term, chi_term in terminology_map.items():
translated_text = translated_text.replace(eng_term, chi_term)
# 检查语法流畅性
# 可以添加更多语法检查和优化逻辑
return translated_text
实战技巧5:创意内容自动生成
节日营销内容创作可以完全自动化。以下代码展示了如何生成节日祝福内容:
import random
def generate_festival_couplets(theme_keywords):
"""根据关键词生成节日对联"""
# 上联生成逻辑
upper_line = f"{theme_keywords}迎春到"
# 下联生成逻辑
lower_line = f"福满{theme_keywords}喜临门"
# 横批生成
horizontal = "新春大吉"
return {
"upper_couplet": upper_line,
"lower_couplet": lower_line,
"horizontal_scroll": horizontal
}
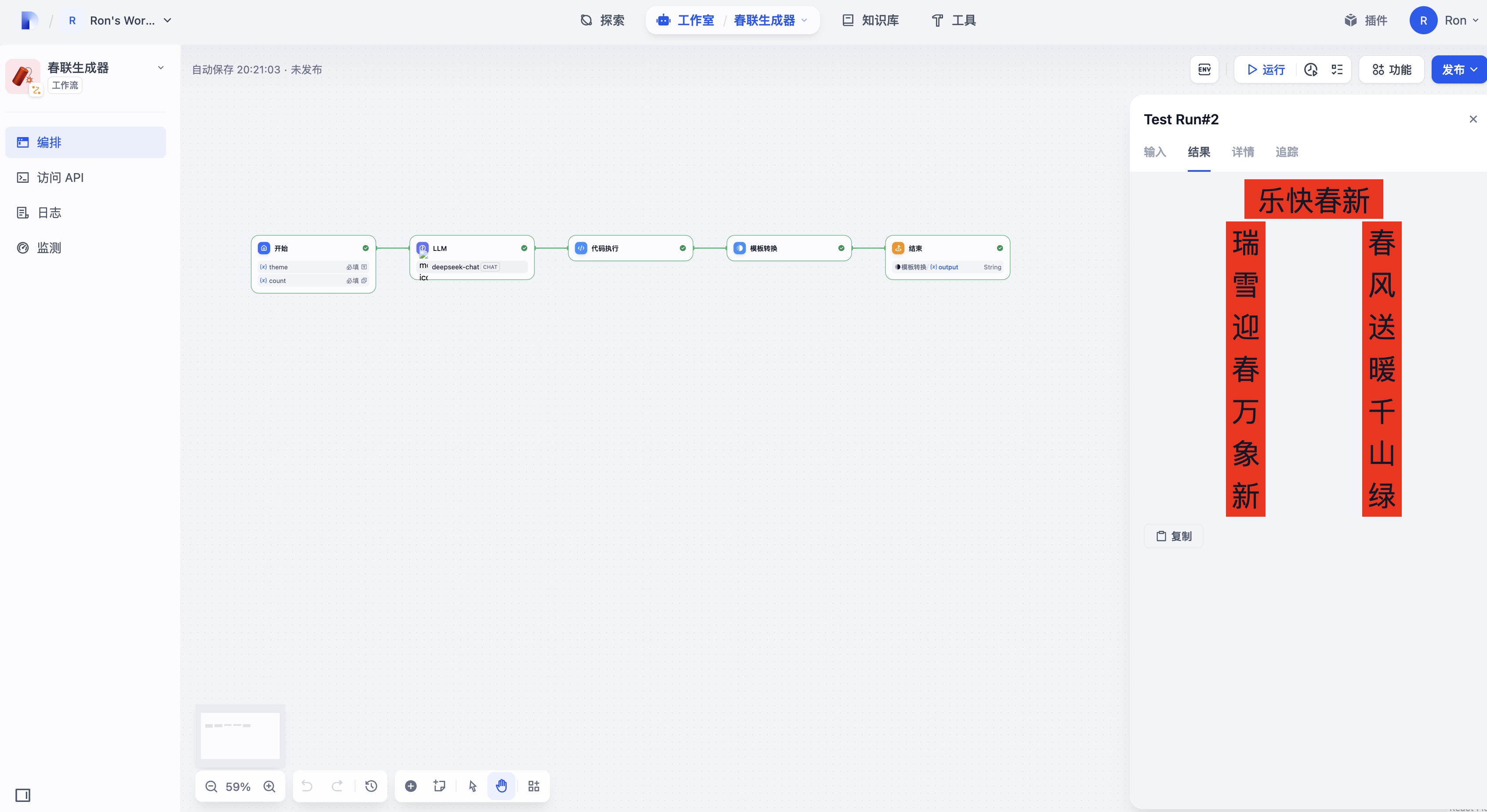
环境配置:避开常见陷阱
沙箱权限问题
默认的Dify沙箱可能存在权限限制。建议使用优化版沙箱dify-sandbox-py,它已经预装了pandas、numpy、matplotlib等常用库。
依赖安装的正确方式
不要在每个代码节点中尝试安装依赖!正确做法是修改沙箱配置文件:
- 打开 `/docker/volumes/sandbox/dependencies/python-requirements.txt`
- 添加需要的依赖包,如 `pandas==2.2.0`
- 重启沙箱容器
字符串长度限制
处理大文本时可能会遇到长度限制。修改.env文件中的配置:
CODE_MAX_STRING_LENGTH: 1000000
TEMPLATE_TRANSFORM_MAX_LENGTH: 1000000
高级应用场景
场景1:智能客服知识库集成
以下工作流展示了如何构建智能客服系统。代码节点可以:
- 解析用户查询意图
- 从知识库检索相关信息
- 生成结构化回复
- 支持图片和文本混合输出
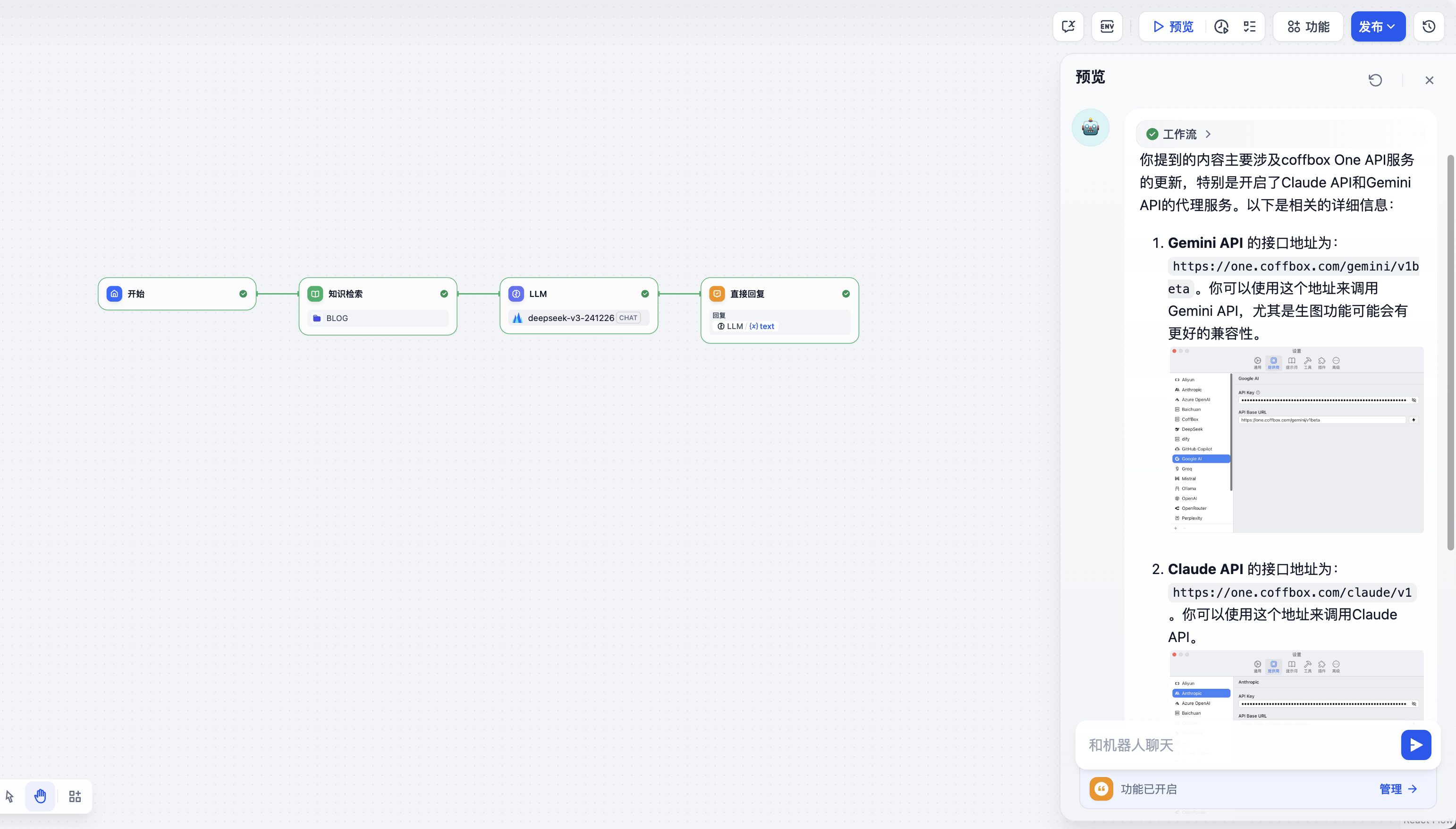
场景2:自动化SEO优化
以下代码可以自动生成SEO友好的URL:
import re
import unicodedata
def create_seo_friendly_url(text):
"""生成SEO友好的URL slug"""
# 转换为小写
text = text.lower()
# 移除特殊字符
text = re.sub(r'[^\w\s-]', '', text)
# 替换空格为连字符
text = re.sub(r'[-\s]+', '-', text)
# 移除首尾连字符
text = text.strip('-')
return text
场景3:多格式文件处理
以下代码展示了如何统一处理不同格式的文件:
import pandas as pd
import json
import csv
def process_file(file_path, file_type):
"""根据文件类型选择读取方式"""
if file_type == 'csv':
return pd.read_csv(file_path)
elif file_type == 'json':
with open(file_path, 'r') as f:
return json.load(f)
elif file_type == 'excel':
return pd.read_excel(file_path)
else:
raise ValueError(f"不支持的文件类型: {file_type}")
性能优化建议
1. 缓存中间结果
对于计算密集型操作,使用缓存避免重复计算:
from functools import lru_cache
@lru_cache(maxsize=128)
def complex_calculation(input_data):
# 耗时计算
result = perform_heavy_processing(input_data)
return result
2. 批量处理数据
避免在循环中频繁调用外部API或进行IO操作:
def process_items_in_batches(items):
"""批量处理提高效率"""
results = []
batch_size = 100
for i in range(0, len(items), batch_size):
current_batch = items[i:i+batch_size]
# 批量处理逻辑
results.extend(process_batch_items(current_batch))
return results
3. 错误处理与重试机制
import time
from tenacity import retry, stop_after_attempt, wait_exponential
@retry(stop=stop_after_attempt(3), wait=wait_exponential(multiplier=1, min=4, max=10))
def call_external_service(data):
"""带重试机制的API调用"""
response = requests.post(service_url, json=data)
response.raise_for_status()
return response.json()
最佳实践总结
- 模块化设计:将复杂逻辑拆分为多个代码节点,每个节点专注单一功能
- 输入验证:在代码开始处验证输入数据的有效性
- 详细日志:使用print()输出关键步骤信息,便于调试
- 异常处理:使用try-except捕获所有可能的异常
- 资源清理:及时关闭文件句柄和数据库连接
- 性能监控:记录关键操作的执行时间
开始你的代码节点之旅
建议从以下工作流开始:
- 初学者:从基本的文件处理和代码执行开始
- 中级用户:尝试数据可视化技巧
- 高级用户:研究复杂系统集成
记住,最好的学习方式就是动手实践。每个工作流都是一个完整的学习案例,包含了从需求分析到实现的全过程。通过研究这些示例,你不仅能掌握代码节点的使用技巧,还能学习到如何设计高效的工作流架构。
代码节点让Dify从"能用"变为"好用",从"工具"变为"平台"。现在就开始你的代码节点之旅,解锁Dify工作流的全部潜力吧!