字节跳动开源大模型强化学习框架verl架构解析与实战指南
大模型后训练时代的强化学习挑战与 verl 的诞生
在大语言模型的后训练阶段,通过强化学习(RL)对齐人类偏好并增强复杂推理能力已成为业界共识。然而,传统 RLHF 流程往往面临显存利用率低、算法实现复杂以及分布式扩展困难等挑战。为此,字节跳动 Seed 团队正式开源了名为 verl 的强化学习训练框架。该框架在系统底层进行了深度优化,不仅将整体训练吞吐量提升了数倍,还极大地简化了高阶 RL 算法的工程落地难度。
核心架构:从 HybridFlow 到工业级 RLHF 框架
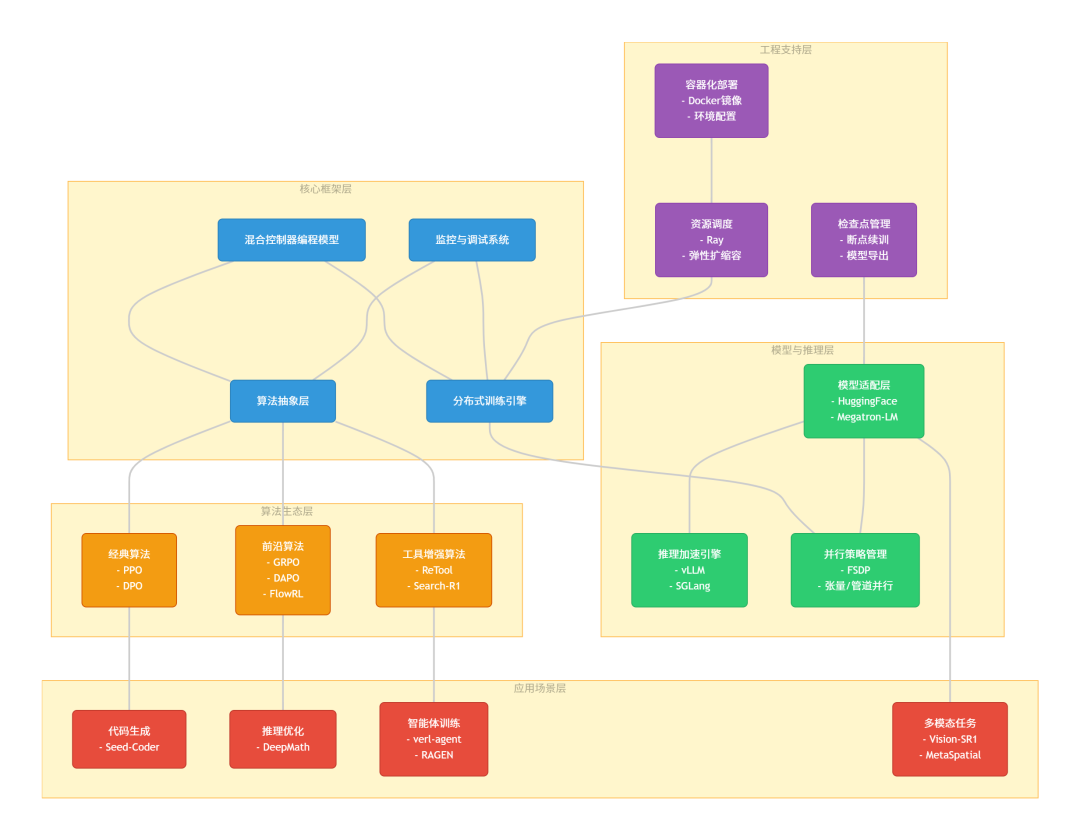
verl 的核心技术底座源自字节跳动内部孵化的 HybridFlow 系统(相关研究成果已被 EuroSys 2025 收录)。作为一个面向生产环境的 RLHF 框架,它针对性地解决了现有开源工具在大规模模型训练中的核心痛点:
- 计算与通信优化:引入 3D-HybridEngine 架构,在模型生成与参数更新阶段实现动态重分片,大幅削减内存冗余,使节点间通信开销下降约 60%。
- 算法开发提效:设计了混合控制器编程范式,开发者仅需编写少量核心逻辑代码,即可快速实现 PPO、GRPO 等复杂策略梯度算法。
- 超大规模分布式支持:无缝集成 FSDP 与 Megatron-LM 等并行策略,具备支撑千亿参数级别(如 671B DeepSeek 模型)训练的能力。
verl 的核心技术特性
1. 丰富的算法生态与极简代码实现
框架内置了超过 15 种主流强化学习算法,覆盖了从基础对齐到复杂推理优化的全场景需求:
- 基础对齐:PPO、DPO、RLOO 等经典算法。
- 推理增强:DAPO(在 AIME 数学基准中表现优异)、VAPO 等。
- 多轮与工具交互:SPPO、ReTool 等针对 Agent 场景优化的算法。
以 GRPO 算法为例,开发者只需通过配置文件指定模型路径与数据集,即可启动分布式训练,无需手动处理复杂的张量切分与梯度同步逻辑:
python -m verl.trainer.main_ppo \
algorithm.adv_estimator=grpo \
data.train_files=/datasets/math_reasoning/train.parquet \
data.val_files=/datasets/math_reasoning/eval.parquet \
data.train_batch_size=512 \
data.max_prompt_length=1024 \
data.max_response_length=2048 \
data.filter_overlong_prompts=True \
actor_rollout_ref.model.path=Qwen/Qwen2.5-7B-Instruct \
actor_rollout_ref.actor.optim.lr=5e-7 \
actor_rollout_ref.actor.ppo_mini_batch_size=128 \
actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=16 \
actor_rollout_ref.actor.use_kl_loss=True \
actor_rollout_ref.actor.kl_loss_coef=0.01 \
actor_rollout_ref.actor.strategy=fsdp \
actor_rollout_ref.rollout.name=vllm \
actor_rollout_ref.rollout.tensor_model_parallel_size=2 \
actor_rollout_ref.rollout.gpu_memory_utilization=0.8 \
actor_rollout_ref.rollout.n=4 \
trainer.project_name='verl_grpo_math_reasoning' \
trainer.experiment_name='qwen2.5_7b_grpo_run1' \
trainer.n_gpus_per_node=8 \
trainer.nnodes=2 \
trainer.save_freq=50 \
trainer.total_epochs=102. 极致的硬件适配与显存优化
为了最大化硬件利用率,verl 在计算引擎与显存管理层面进行了深度定制:
- 推理加速集成:原生支持 vLLM 与 SGLang 等高性能推理引擎,使 Rollout 阶段的生成吞吐量提升约 3 倍。
- 显存优化技术:全面接入 FlashAttention2 与 Liger-kernel,结合细粒度的 GPU 映射策略,使峰值显存占用降低 40% 以上。
- 训推分离部署:支持将训练节点与推理节点物理隔离,避免显存碎片化问题。
3. 生产级工程保障与多模态扩展
在工程化落地方面,框架提供了完善的容错与监控机制:
- 断点续训与监控:支持全局训练状态的秒级快照与恢复,并深度集成 Weights & Biases (wandb) 和 MLflow,实现训练指标的实时可视化。
- 弹性资源调度:基于 Ray 构建分布式调度层,可轻松管理数百张 GPU 的异构集群。
- 多模态原生支持:打破纯文本限制,支持 Qwen2.5-VL 等视觉语言模型的 RLHF 训练,适用于图文混合指令跟随与多模态工具调用场景。
标准工作流与快速上手指南
环境配置
建议通过以下命令完成框架及其加速依赖的安装:
# 克隆仓库并安装基础依赖
git clone https://github.com/volcengine/verl.git
cd verl
pip install -e .
# 安装 CUDA 加速与 vLLM 推理引擎相关依赖
pip install -e ".[vllm]"典型 RLHF 工作流

- 监督微调 (SFT):使用高质量指令数据集对基座模型进行初步对齐。
- 奖励模型 (RM) 训练:基于人类偏好数据训练评分模型,为后续 RL 提供奖励信号。
- 强化学习优化 (RL):选择合适的算法(如 PPO 或 GRPO)进行策略迭代,提升模型在特定任务上的表现。
- 评估与部署:将训练好的模型导出,并结合 vLLM 等框架部署为高并发推理服务。
未来技术演进路线
根据官方开源路线图,verl 在后续版本中将重点推进以下技术方向:
- 构建异步离线策略架构,进一步解耦数据生成与参数更新。
- 完善多智能体(Multi-Agent)协同训练的底层支持。
- 针对超大规模 MoE(混合专家)模型进行通信与计算图优化。
- 深化强化学习与外部工具调用(Tool Learning)的融合机制。
