基于深度学习的交通标志检测系统设计与实现
- 系统概述 随着智能交通系统的快速发展,交通标志自动识别技术在自动驾驶和辅助驾驶中扮演着关键角色。本文介绍一种基于YOLOv5架构的实时交通标志检测系统,适用于国内道路环境,具备高精度与快速响应能力,适合作为高校毕业设计项目。
该系统融合了现代目标检测算法的优势,在自研数据集上实现了良好的检测性能。整体方案包含数据预处理、模型构建、训练优化及可视化部署等完整流程,具有较强的工程实践价值。
- 核心算法解析
2.1 YOLOv5 检测机制 YOLOv5 是一种单阶段(one-stage)目标检测框架,相较于两阶段方法如Faster R-CNN,其优势在于推理速度快、资源消耗低,适合嵌入式设备部署。本项目采用YOLOv5s版本作为基础网络,在保证精度的同时控制模型体积。
主要改进点包括:
- Mosaic 数据增强:通过拼接四幅图像提升小样本学习能力;
- CSP 主干结构:减少计算量并增强梯度传播效果;
- FPN+PAN 特征金字塔:融合多层特征以提升对不同尺度目标的敏感性;
- GIoU Loss 与 DIOU NMS:优化边界框回归精度,抑制重复检测。
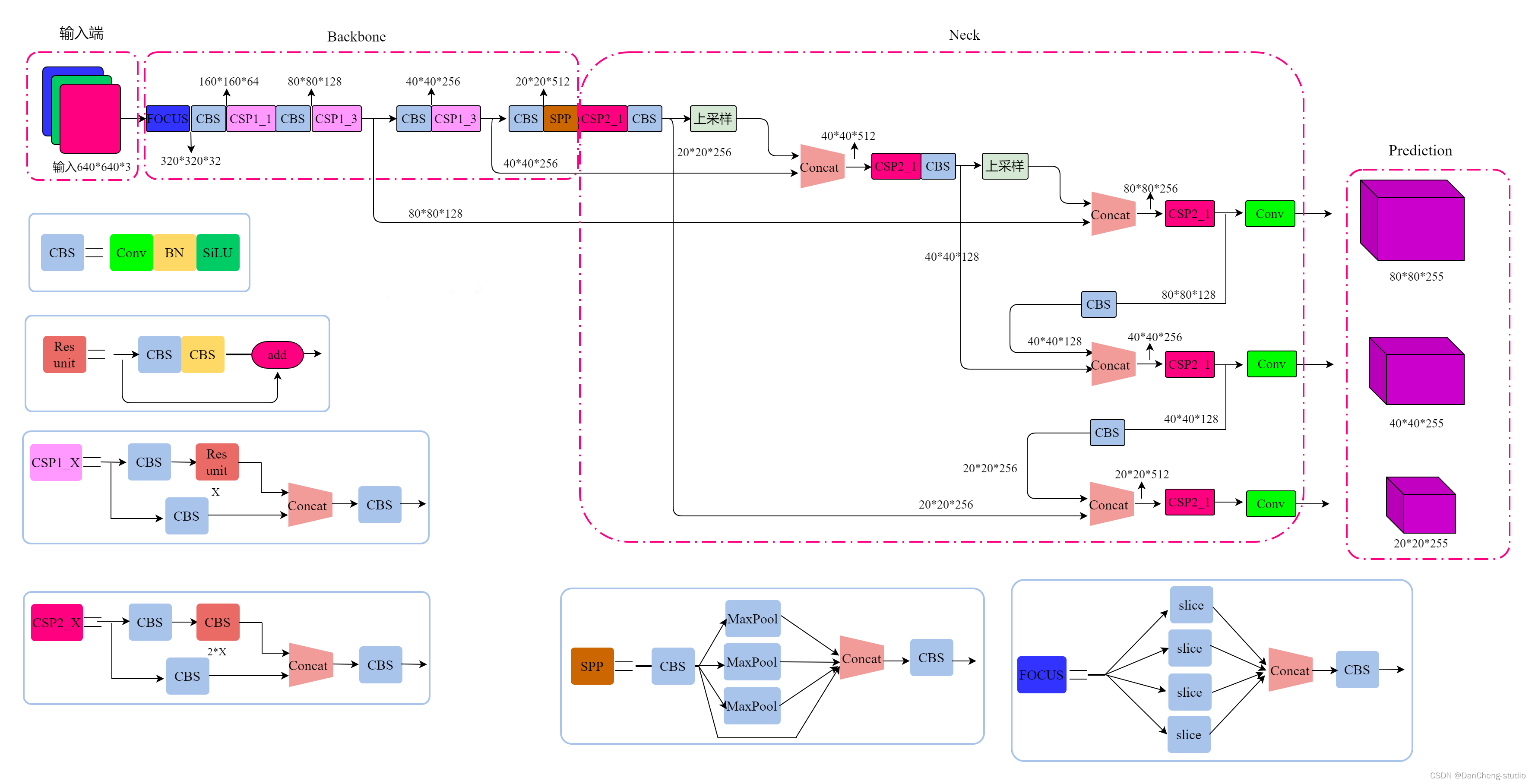
2.2 模型结构组成 整个网络可分为四个部分:
- 输入端:支持动态尺寸输入,使用归一化与Mosaic增强策略提升泛化能力;
- 主干网络(Backbone):采用CSPDarknet53提取基础特征,并引入Focus模块进行通道重组;
- 颈部网络(Neck):结合FPN与PAN结构实现双向特征融合,强化高层语义与底层细节的结合;
- 检测头(Head):输出分类与定位结果,每个预测层对应不同的感受野,适应多种尺寸标志。
- 关键代码重构示例
以下为检测头核心类的重写实现,增强了可读性和模块独立性:
import torch
import torch.nn as nn
class DetectionHead(nn.Module):
def __init__(self, num_classes=80, anchor_list=None, input_channels=None):
super().__init__()
self.num_classes = num_classes
self.total_outputs = num_classes + 5 # 类别数 + 坐标偏移 + 置信度
self.num_layers = len(anchor_list)
self.num_anchors_per_layer = len(anchor_list[0]) // 2
self.anchors = nn.Parameter(torch.tensor(anchor_list).float().view(self.num_layers, -1, 2))
self.stride = torch.ones(self.num_layers)
# 输出卷积层列表
self.conv_layers = nn.ModuleList(
nn.Conv2d(in_ch, self.total_outputs * self.num_anchors_per_layer, 1)
for in_ch in input_channels
)
self.grid_cells = [torch.zeros(1)] * self.num_layers
self.anchor_grids = [torch.zeros(1)] * self.num_layers
def forward(self, feature_maps):
predictions = []
outputs = []
for i, x in enumerate(feature_maps):
x = self.conv_layers[i](x)
batch_size, _, height, width = x.shape
# 重塑输出为 (batch, anchors, grid_h, grid_w, output_dim)
x = x.view(batch_size, self.num_anchors_per_layer, self.total_outputs, height, width)
x = x.permute(0, 1, 3, 4, 2).contiguous()
if not self.training:
if self.grid_cells[i].shape[2:4] != x.shape[2:4]:
self.grid_cells[i], self.anchor_grids[i] = self._generate_grid(width, height, i)
pred = x.sigmoid()
pred_xy = (pred[..., 0:2] * 2 - 0.5 + self.grid_cells[i]) * self.stride[i]
pred_wh = (pred[..., 2:4] * 2) ** 2 * self.anchor_grids[i]
pred_bbox = torch.cat((pred_xy, pred_wh, pred[..., 4:]), dim=-1)
outputs.append(pred_bbox.view(batch_size, -1, self.total_outputs))
predictions.append(x)
return predictions if self.training else (torch.cat(outputs, 1), predictions)
def _generate_grid(self, w, h, idx):
device = self.anchors.device
yv, xv = torch.meshgrid(torch.arange(h, device=device), torch.arange(w, device=device), indexing='ij')
grid = torch.stack((xv, yv), 2).expand(1, self.num_anchors_per_layer, h, w, 2).float()
anchor_sizes = (self.anchors[idx].clone() * self.stride[idx]).view(1, self.num_anchors_per_layer, 1, 1, 2)
return grid, anchor_sizes
- 数据集构建与标注
本项目使用由中国长沙理工大学发布的 CCTSDB(Chinese City Traffic Sign Detection Benchmark)数据集,涵盖超过一万张真实道路场景下的交通标志图像,类别丰富,贴合国情。
4.1 VOC 数据组织格式 为兼容主流检测框架,需将原始数据转换为PASCAL VOC标准结构:
dataset/
├── JPEGImages/ # 存放所有图片,命名格式为六位数字,如 000001.jpg
├── Annotations/ # 对应XML标注文件,与图片同名
└── ImageSets/Main/ # 划分训练集、验证集、测试集的txt列表
├── train.txt
├── val.txt
├── trainval.txt
└── test.txt
每张图像的标注信息包含目标类别、边界框坐标(xmin, ymin, xmax, ymax),存储于XML文件中。
4.2 数据标注工具推荐 对于自定义扩展数据集,推荐使用开源标注工具 LabelImg:
pip install labelimg
labelimg
该工具支持VOC XML格式导出,界面简洁,操作直观,广泛应用于学术研究与工业开发。
4.3 数据筛选建议 实际使用中发现,CCTSDB 后半部分存在较多无标注或标签缺失图像。建议优先选用前4000张已完成标注的数据,既能满足训练需求,又避免繁琐的手动清洗过程。
- 模型训练配置
训练脚本 train.py 中的关键参数设置如下:
cfg: 指定模型结构文件 yolov5s.yamldata: 自定义数据配置文件 data/cctsdb.yamlepochs: 训练轮次,建议设置为100~300batch_size: 批次大小,根据显存调整(16或32)img_size: 输入分辨率,常用640×640device: 使用GPU设备编号,如 '0' 或 'cpu'workers: 数据加载线程数,一般设为8
训练过程中会自动记录损失曲线、mAP指标及权重文件,保存至 runs/train/expX 目录下。
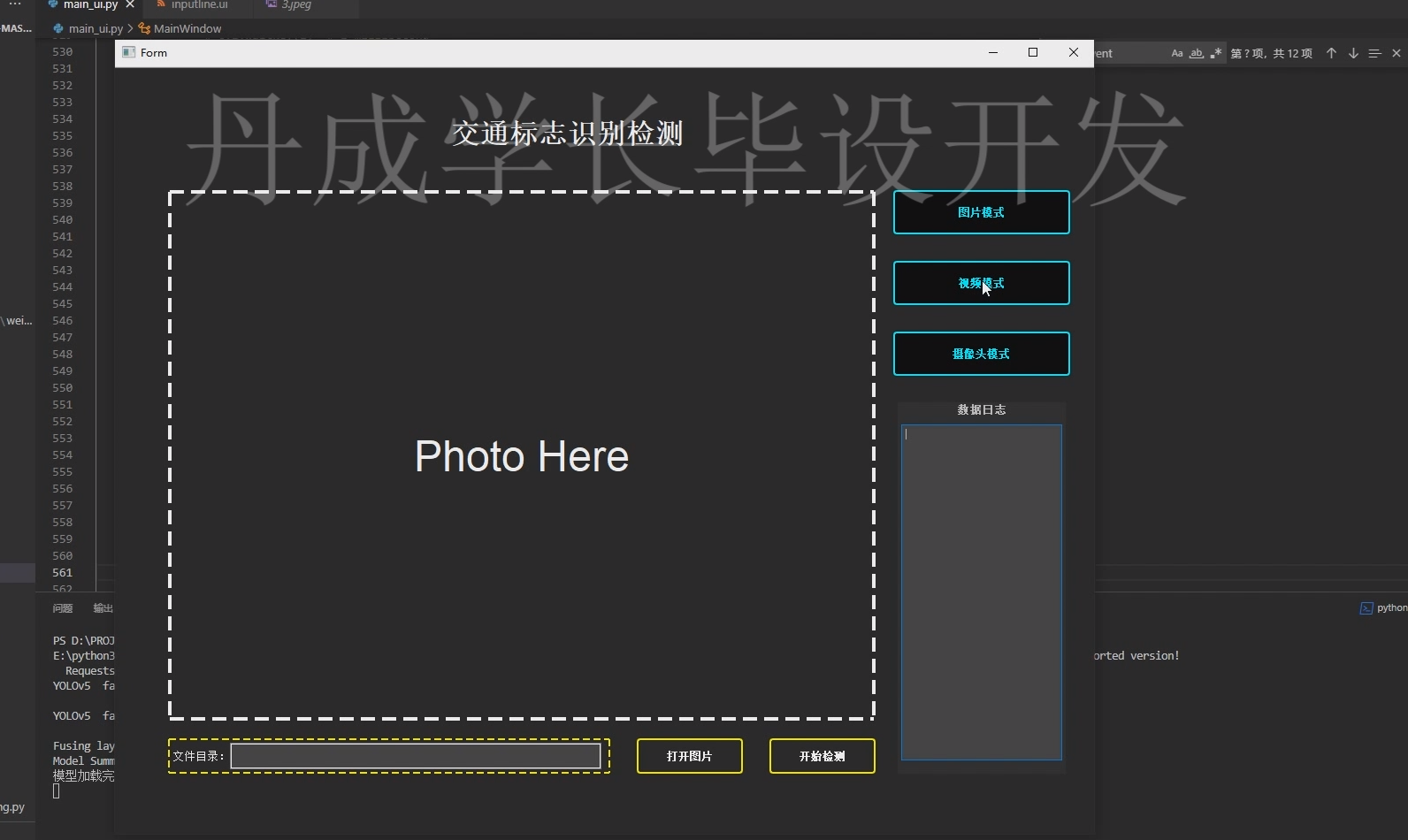
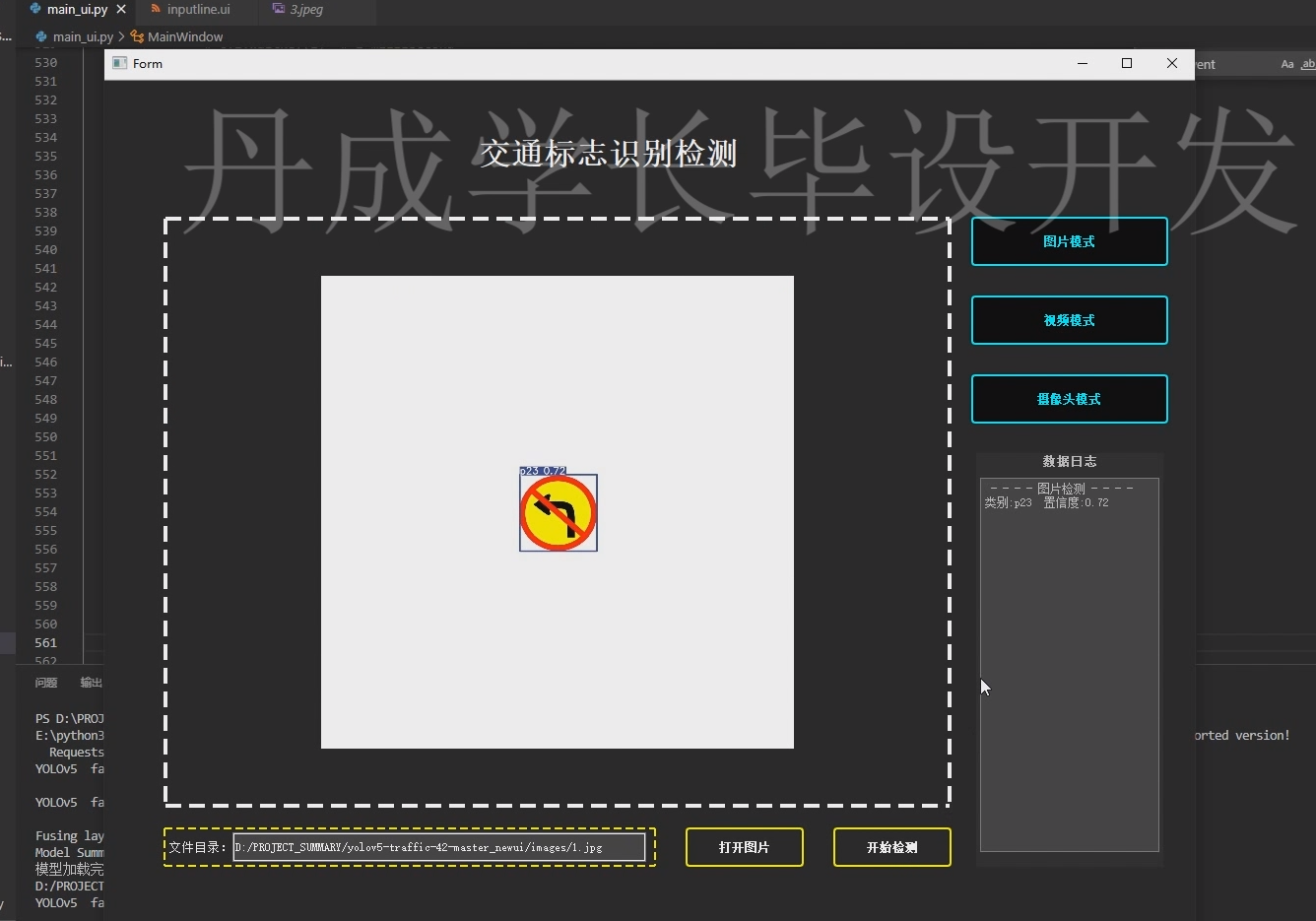
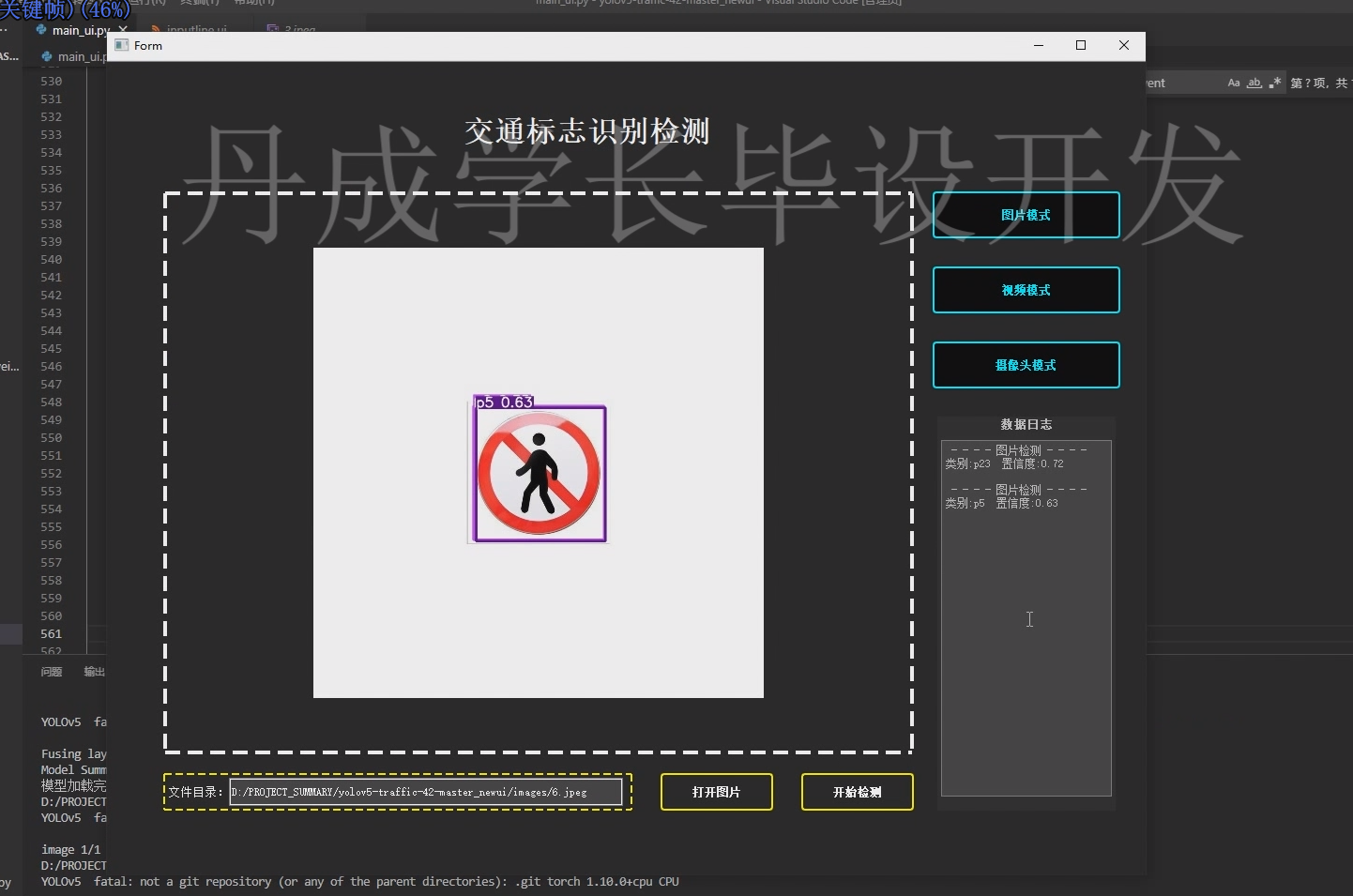
- 运行效果展示
系统可在摄像头视频流或静态图像中实现实时检测,准确识别禁止通行、限速、让行等多种常见交通标志。检测结果以彩色边框标注,并显示类别名称与置信度分数。
支持导出检测日志、生成性能报告,便于分析模型表现。
浏览器不支持视频播放
