使用LoRA技术微调Qwen3嵌入模型:提升垂直领域语义搜索性能
Qwen3嵌入模型概述
阿里巴巴最近发布了Qwen3嵌入模型系列,在MTEB排行榜上取得了多个第一名的优异成绩,并且整个模型系列完全开源。这一系列模型为检索增强生成(RAG)技术栈提供了完整的解决方案。
在RAG架构中:
- 语义召回层可使用Qwen3 Embedding模型
- 召回排序层可使用Qwen3 Reranking模型
- 生成层可使用Qwen3 Chat模型
本文将介绍Qwen3嵌入模型系列,并通过实战演示如何使用LoRA技术将通用嵌入模型微调为特定领域的嵌入模型,以提升该领域的语义搜索性能。
Qwen3模型架构
Qwen3主要包含两个模型系列:嵌入模型系列和重排序模型系列。
嵌入模型
嵌入模型以单个文本片段作为输入,通过提取与结束符([EOS])标记对应的隐藏状态向量来生成语义表示。
重排序模型
重排序模型以文本对(如用户查询与候选文档)作为输入,抽取最后一层中"yes"和"no"这两个token的logit值,经过log_softmax处理后,取"yes"所在位置的分数作为最终得分。
# 重排序模型得分计算示例
false_token_id = tokenizer.convert_tokens_to_ids("no")
true_token_id = tokenizer.convert_tokens_to_ids("yes")
def calculate_pair_scores(inputs, **kwargs):
batch_logits = model(**inputs).logits[:, -1, :]
false_scores = batch_logits[:, false_token_id]
true_scores = batch_logits[:, true_token_id]
score_pairs = torch.stack([false_scores, true_scores], dim=1)
log_probabilities = torch.nn.functional.log_softmax(score_pairs, dim=1)
final_scores = log_probabilities[:, 1].exp().tolist()
return final_scores
三阶段分层训练机制
Qwen3嵌入模型采用三阶段分层训练机制:
- 对比预训练阶段:使用海量弱监督数据增强模型泛化能力
- 精调阶段:采用高质量标注数据进行监督训练,提升任务适配性
- 模型融合阶段:通过集成策略合并多个候选模型,实现性能突破
LoRA微调实战
负样本构建策略
对于嵌入模型和重排序模型,负样本的构建至关重要。本文使用sentence_transformers库中的mine_hard_negatives方法挖掘难负样本,通过参数调整筛选出相似但不相关的样本。
数据来源:农林牧渔中文问答数据集
负样本挖掘流程
- 相似度计算和候选生成:使用嵌入模型或重排序模型计算查询与语料库的相似度,获取top-k最相似候选
- 负样本筛选:排除正例后,应用多种筛选条件:
- absolute_margin:绝对相似度差异阈值
- relative_margin:相对相似度比例阈值
- max_score/min_score:相似度分数阈值
# 负样本挖掘实现示例
from datasets import load_dataset
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import mine_hard_negatives
# 加载数据集
qa_dataset = load_dataset("parquet", data_files="/path/to/agricultural_qa_data.parquet")
split_dataset = qa_dataset["train"].train_test_split(test_size=0.95, seed=42)
# 加载基础嵌入模型
base_embed_model = SentenceTransformer("/path/to/base_embedding_model")
# 挖掘难负样本
hard_negatives_dataset = mine_hard_negatives(
split_dataset['train'],
base_embed_model,
anchor_column_name="query",
positive_column_name="answer",
num_negatives=5,
range_min=20,
range_max=50,
max_score=0.8,
absolute_margin=0.1,
sampling_strategy="top",
batch_size=64,
output_format="labeled-list",
use_faiss=True
)
# 数据格式转换
def transform_data_format(example):
correct_answer = next(ans for ans, label in zip(example['answer'], example['labels']) if label == 1)
rejected_answers = [ans for ans, label in zip(example['answer'], example['labels']) if label == 0]
return {
"question": example['query'],
"correct_answer": correct_answer,
"rejected_answers": rejected_answers
}
transformed_dataset = hard_negatives_dataset.map(transform_data_format, remove_columns=hard_negatives_dataset.column_names)
transformed_dataset.to_json("./processed_data/qwen3_emb_finetune.json", force_ascii=False)
InfoNCE损失函数
训练采用InfoNCE损失函数,带有负样本:
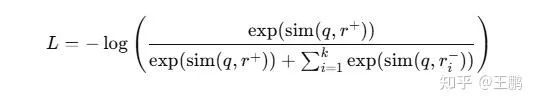
其中:
- q是查询(query)的嵌入向量
- r+是对应正样本的嵌入向量
- r-是对应负样本的嵌入向量
- sim表示点积或余弦相似度
该损失函数会惩罚查询与负样本相似度过高的情况,鼓励查询与正样本的相似度更高。
微调实现
数据格式
微调数据格式如下:correct_answer为正样本,rejected_answers为负样本列表。
{
"question": "绿色对老年人有哪些健康益处?",
"correct_answer": "绿色环境可以帮助老年人放松紧张的中枢神经,改善和调节身体功能,降低皮肤温度,减少脉搏和呼吸频率,保持血压稳定,减轻心脏负担,提供精神舒适感。这对于冠心病、高血压患者以及身体机能退化的老年人尤为有益。",
"rejected_answers": [
"绿茶的主要功效是预防癌症和心血管疾病,还能抗氧化,提高免疫力,抑制和杀灭细菌等;白茶的主要功效有保护脑神经,增强记忆,减少焦虑等。",
"绿茶水洗脸可以防止肌肤衰老,抗辐射,尤其适合长期用电脑的女性,可抑制皮肤色素沉着,减少过敏反应的发生。",
"绿色食物代表有花椰菜,菠菜,芦笋。它们具有超强的减肥功效,每杯绿果蔬的热量还不到50千卡,适合于大量食用;它们含有的抗氧化剂具有延长寿命的功效。",
"生态养殖可以改善肉、蛋、奶品质,能生产出天然绿色食品。",
"绿水对锦鲤有发色和提供营养的作用,还能对锦鲤有一定的康复作用。锦鲤在游动时可能会遇到小的擦伤,将鱼放在绿水中进行调养可以促进康复。"
]
}
训练配置
# 使用ms-swift进行LoRA微调
INFONCE_MASK_FAKE_NEGATIVE=True
swift sft \
--model /path/to/Qwen3-Embedding-0.6B \
--task_type embedding \
--model_type qwen3_emb \
--train_type lora \
--dataset /path/to/processed_data/qwen3_emb_finetune.json \
--split_dataset_ratio 0.05 \
--eval_strategy steps \
--output_dir ./fine_tuned_output \
--eval_steps 100 \
--num_train_epochs 1 \
--save_steps 100 \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--gradient_accumulation_steps 4 \
--learning_rate 6e-6 \
--loss_type infonce \
--label_names labels \
--dataloader_drop_last true
关键参数说明
--task_type embedding:指定任务类型为嵌入模型训练--model_type qwen3_emb:指定模型类型为Qwen3嵌入模型--loss_type infonce:使用InfoNCE损失函数--train_type lora:采用LoRA微调方法
训练结果分析
训练过程中,损失函数持续下降,正负样本的区分度(margin)从0.20提升至0.235。其中margin定义为sim(q,r+) - sim(q,r-),表明模型对正负样本的区分能力显著增强。
评估指标
- 评估损失:模型在验证集上的损失值变化
- 样本区分度:正负样本相似度差异的变化
- 负样本质量:被拒绝样本与查询的相似度分布
性能提升
微调后的模型在农林牧渔领域的语义搜索任务中表现出色,特别是在处理专业术语和领域特定查询时,检索准确率相比通用模型有明显提升。
结论
通过LoRA技术微调Qwen3嵌入模型,可以有效地将通用嵌入模型转化为特定领域的专业模型,显著提升在垂直领域的语义搜索性能。这种方法不仅计算效率高,而且能够充分利用预训练模型的知识,同时快速适应特定领域的需求。
负样本挖掘和InfoNCE损失函数的结合使用,确保了模型能够学习到更精确的语义表示,从而在检索任务中表现出色。这种微调方法可以广泛应用于各种垂直领域的语义搜索和推荐系统。
