基于Chameleon-LLM的多模态推理与工具协同实战指南
框架概述:实现语言模型与外部工具的动态协同
Chameleon-LLM 是一个开源的可组合推理框架,旨在增强大型语言模型(LLMs)在复杂任务中的表现。其核心设计理念是将 LLM 作为"自然语言控制器",根据输入问题动态调度并协调多个专业工具完成推理流程。该架构特别适用于需要跨模态理解(如图文结合、表格分析)和多步骤逻辑推导的应用场景。
系统支持多种异构工具接入,包括:
- 文本生成服务(如 GPT-4、Llama 系列)
- 图像描述模型(Hugging Face 提供的视觉编码器)
- 结构化数据处理器(用于解析表格内容)
- 搜索引擎接口(Bing API 实现知识检索)
- 代码执行引擎(运行生成的 Python 脚本)

性能优势:为何选择插件式推理架构?
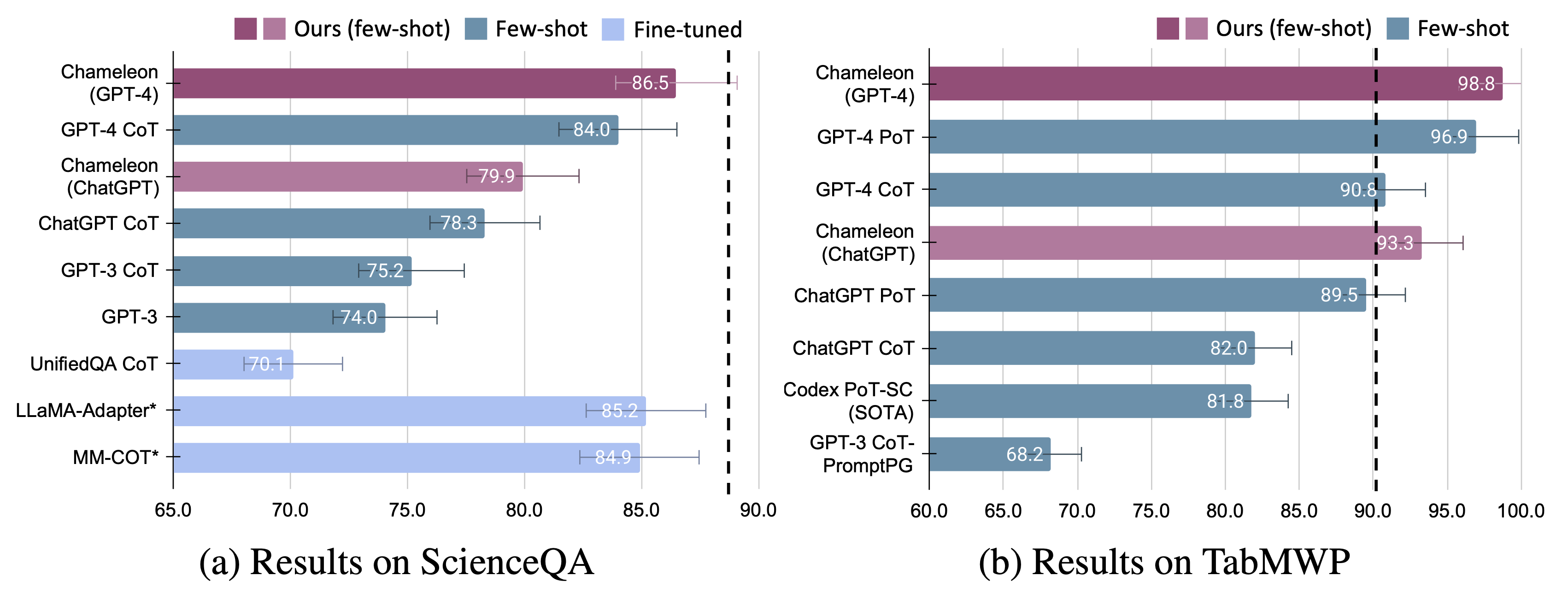
传统方法依赖单一模型进行端到端预测,在面对科学问答或数学建模等复合型任务时存在明显局限。Chameleon 通过模块化分工显著提升了准确率:
- 在 ScienceQA 数据集上,使用 GPT-4 作为决策主控时,准确率达到 86.54%
- 在 TabMWP 表格数学题数据集上,得分高达 98.78%,远超微调模型与少样本提示方法
这一提升源于智能的任务分解机制。实验数据显示,当采用更强大的 LLM(如 GPT-4 对比 ChatGPT)作为策略规划器时,系统能更合理地分配工具调用频率,避免冗余操作,提升整体效率。
环境配置与项目初始化
要开始使用 Chameleon-LLM,请按以下步骤部署本地开发环境:
1. 克隆源码仓库
git clone https://gitcode.com/gh_mirrors/ch/chameleon-llm
cd chameleon-llm
2. 安装运行依赖
pip install -r requirements.txt
关键依赖项包括:
- Python >= 3.8
- openai
- transformers
- torch
- pandas, numpy
- huggingface-hub
3. 设置认证密钥
编辑配置文件或设置环境变量以启用相关服务:
- OpenAI API Key:必选,用于调用 GPT 系列模型
- Bing Search API Key:可选,用于外部知识检索模块
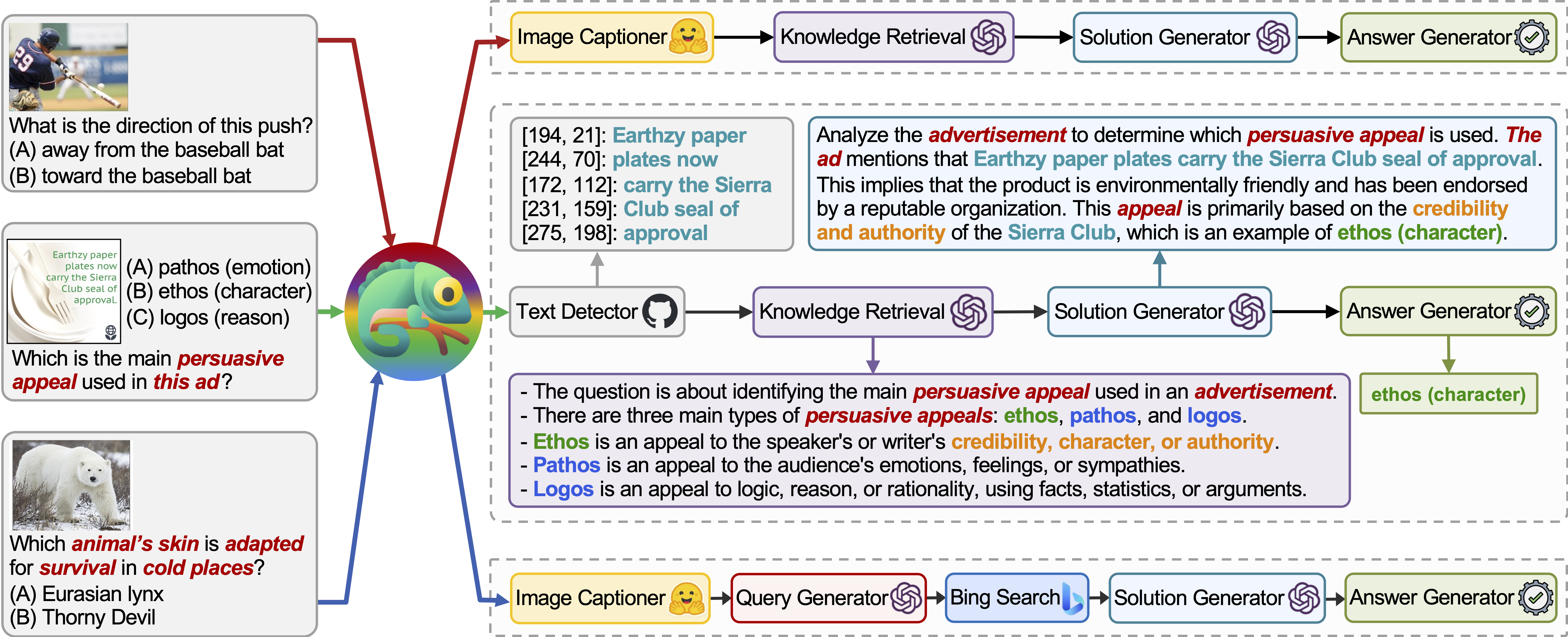
实战演练:在科学问答任务中应用 Chameleon
进入示例目录并执行推理脚本:
cd run_scienceqa
python run.py \
--model chameleon \
--label chameleon_gpt4 \
--policy_engine gpt-4 \
--kr_engine gpt-4 \
--qg_engine gpt-4 \
--sg_engine gpt-4 \
--test_split test \
--test_number -1
上述命令含义如下:
--policy_engine:指定主控模型负责任务规划--kr_engine:知识检索模块使用的模型--qg_engine:问题重写或细化组件--sg_engine:最终答案生成器--test_number -1:测试全部样本
结果评估
运行完成后,使用内置评估脚本分析输出:
python evaluate.py \
--data_file ../data/scienceqa/problems.json \
--result_root ../results/scienceqa \
--result_files chameleon_gpt4_test_cache.jsonl
输出文件说明:
chameleon_gpt4_test.json:最终预测结果chameleon_gpt4_test_cache.jsonl:逐轮中间状态日志chameleon_gpt4_test_cache.json:结构化缓存快照
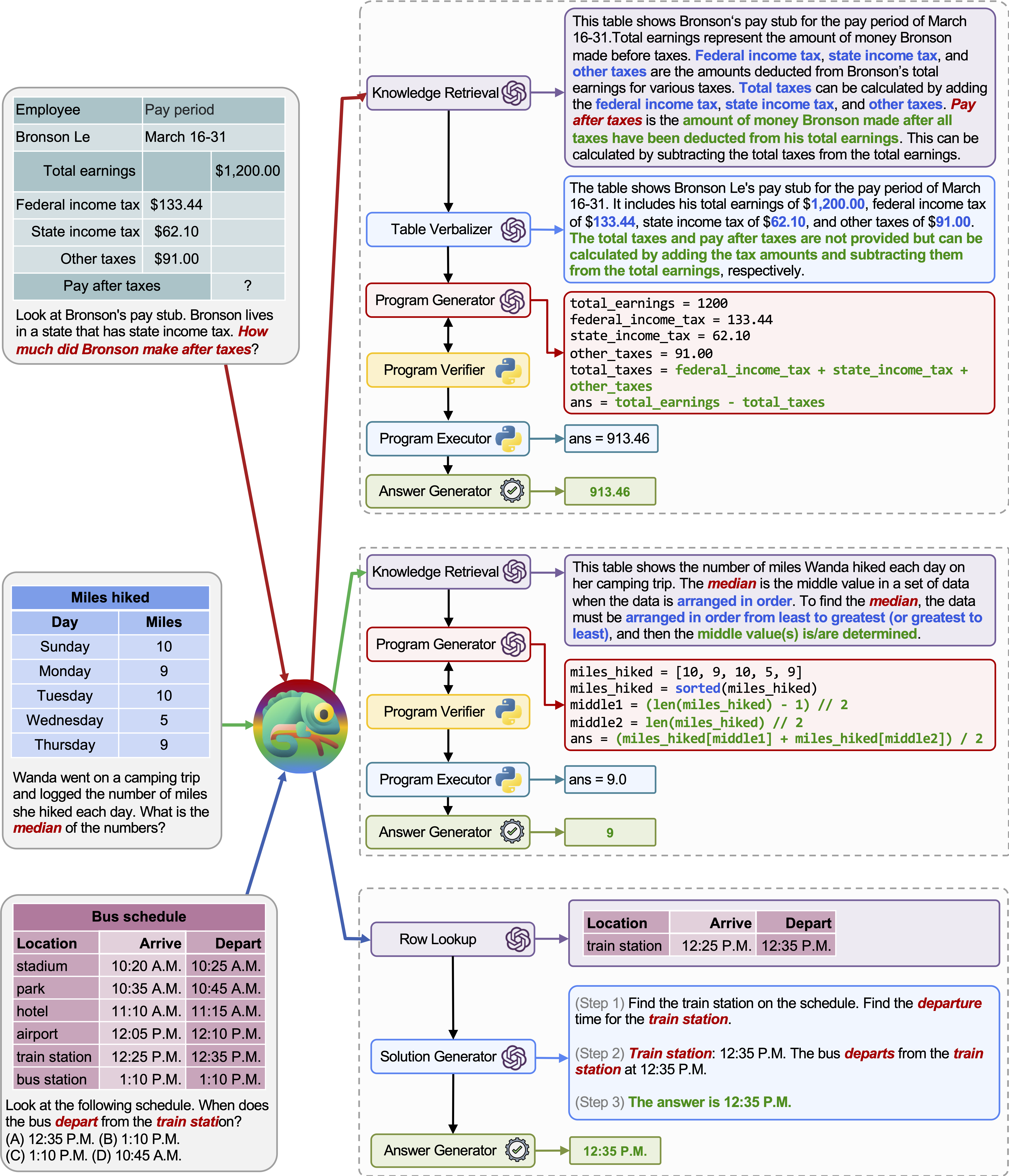
进阶案例:处理表格中的数学问题(TabMWP)
对于涉及表格理解和数值计算的任务,Chameleon 展现出更强的适应性。以下是运行 TabMWP 示例的完整命令:
cd run_tabmwp
python run.py \
--model chameleon \
--label chameleon_gpt4 \
--test_split test \
--policy_engine gpt-4 \
--rl_engine gpt-4 \
--cl_engine gpt-4 \
--tv_engine gpt-4 \
--kr_engine gpt-4 \
--sg_engine gpt-4 \
--pg_engine gpt-4 \
--test_number -1 \
--rl_cell_threshold 18 \
--cl_cell_threshold 18
其中新增参数解释:
--rl_engine:行级信息提取模型--cl_engine:列级语义解析器--tv_engine:表格值读取模块--pg_engine:程序生成引擎,输出可执行数学表达式--*_cell_threshold:控制单元格数量触发转换逻辑
扩展开发:构建自定义任务流程
若需将 Chameleon 应用于新领域,建议遵循以下开发流程:
- 定义模块库:在
demos/目录下创建各工具的提示模板;在model.py中声明输入/输出格式及执行逻辑 - 训练规划代理:向主控 LLM 提供清晰的模块功能描述与调用样例,使其学会将用户请求映射为工具调用序列
- 集成数据接口:实现新的数据加载器,并更新
main.py中的评估函数以支持新任务指标
学习资源与后续探索
- 数据资源:ScienceQA 和 TabMWP 数据集位于
data/子目录 - 可视化工具:Jupyter Notebook 分析脚本存放于
notebooks/result_analysis - 原始论文:Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models
