VALL-E X 零样本多语言语音合成与声音克隆技术解析
VALL-E X 技术架构与原理解析
VALL-E X 是基于微软前沿研究构建的开源零样本文本转语音(TTS)框架。与传统依赖大量特定说话人数据进行微调的自回归模型不同,该系统将语音合成任务转化为神经编解码器的语言建模问题。其核心架构依赖于跨语言神经编解码器,能够将离散的音频标记(Audio Tokens)与文本序列进行对齐和生成。
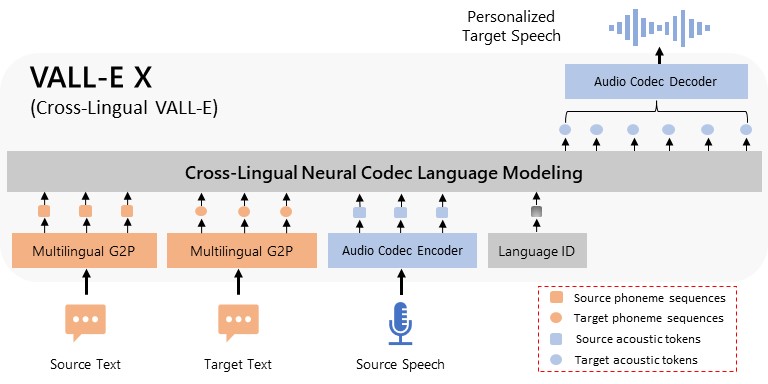
如上图所示,整个推理管线包含了多语言字音转换(G2P)模块、音频编解码器以及语言标识(Language ID)嵌入。系统首先通过 G2P 模块将输入文本转化为音素序列,随后结合参考音频提取的声学特征,自回归地预测目标语音的离散编码,最终通过声码器还原为高保真波形。
核心能力特性
跨语言零样本推理
该模型原生具备处理中文、英文和日文等多语种混合文本的能力。通过内置的 utils/g2p 字典与规则引擎,系统能够精准处理不同语言环境下的多音字和音素映射。在零样本(Zero-shot)设定下,模型无需针对特定语言或说话人进行梯度更新,即可直接输出自然流畅的跨语言语音。
高保真声音克隆
借助强大的提示学习(Prompt Learning)机制,VALL-E X 仅需 3 到 10 秒的参考音频(Prompt Audio)即可捕获目标说话人的音色、语调和韵律特征。开发者可以通过修改 presets 目录下的配置,注入不同的情感标签(如中性、喜悦、愤怒),从而在保持原音色不变的前提下控制生成语音的情感表现力。
工程部署与代码实践
为了在本地环境中快速构建 VALL-E X 的推理服务,我们可以通过编写自动化脚本来完成环境隔离与依赖安装,并直接使用 Python API 进行音频合成。
环境初始化
以下 Shell 脚本用于创建独立的虚拟环境并拉取核心代码库:
#!/bin/bash
# setup_vallex.sh - 自动化环境配置脚本
WORKSPACE="vallex_inference_env"
mkdir -p "$WORKSPACE" && cd "$WORKSPACE"
# 获取源代码
git clone https://github.com/Plachtaa/VALL-E-X.git .
# 配置 Python 虚拟环境
python3 -m venv .venv
source .venv/bin/activate
# 升级包管理工具并安装依赖
pip install --upgrade pip setuptools
pip install -r requirements.txt
推理代码实现
相较于使用图形界面,在工程落地中通常需要通过代码直接调用推理接口。以下 Python 示例展示了如何加载模型、提取说话人嵌入(Speaker Embedding)并生成目标音频:
import torch
from models.vallex import VALLEX
from utils.audio_processing import save_waveform
def generate_cloned_speech(input_text, reference_audio, output_path, lang_code="zh"):
# 硬件加速配置
compute_device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 加载预训练的 VALL-E X 模型
tts_model = VALLEX.from_pretrained("vallex_base_checkpoint").to(compute_device)
tts_model.eval()
# 从参考音频中提取音色特征向量
speaker_prompt = tts_model.extract_speaker_embedding(reference_audio)
# 文本音素化及声学特征自回归生成
phoneme_sequence = tts_model.text_to_phonemes(input_text, language=lang_code)
with torch.no_grad():
acoustic_tokens = tts_model.predict_acoustic(phoneme_sequence, speaker_prompt)
# 神经编解码器解码为时域波形
audio_waveform = tts_model.decode_to_waveform(acoustic_tokens)
# 持久化音频文件
save_waveform(audio_waveform, output_path, sample_rate=24000)
print(f"合成完成,文件已保存至: {output_path}")
if __name__ == "__main__":
target_script = "这是一段用于验证多语言零样本声音克隆效果的测试音频。"
prompt_wav_path = "./prompts/speaker_reference.wav"
generate_cloned_speech(
input_text=target_script,
reference_audio=prompt_wav_path,
output_path="./outputs/cloned_result.wav",
lang_code="zh"
)
行业应用场景
多语种内容本地化
在视频出海与全球化播客制作中,VALL-E X 的跨语言生成能力允许创作者使用原声演员的音色,直接生成其他语言的配音。这不仅大幅降低了多语种配音的成本,还保证了角色声音在不同语言版本中的一致性。
虚拟数字人与智能交互
结合自定义音素表(如 customs/ph.txt 中的扩展配置),开发者可以为虚拟助手或数字人打造极具个性化的语音交互模块。零样本特性使得系统能够根据用户的实时文本输入,动态生成带有特定情感和口音的语音反馈,显著提升人机交互的沉浸感。
