ComfyUI节点化图像生成与LoRA高效微调技术解析
ComfyUI 架构与节点化工作流
1. 核心概念与组件
图形用户界面(GUI)通过可视化组件实现人机交互。在AI图像生成领域,ComfyUI 采用了一种基于节点(Node-based)的架构设计。它将复杂的扩散模型推理过程解耦为多个独立的功能模块,用户通过连线构建有向无环图(DAG),从而实现高度定制化的生成管线。
关键模块解析
- 检查点加载器(Load Checkpoint):负责解析并加载基础大模型文件,通常包含扩散模型(UNet)、文本编码器(CLIP)和变分自编码器(VAE)三大核心组件。
- 文本编码器(CLIP):将自然语言提示词(Prompt)映射到高维潜在空间(Latent Space),生成模型可解析的条件嵌入向量。
- 采样器(KSampler):控制扩散过程的去噪迭代。Stable Diffusion 的本质是将纯噪声逐步还原为清晰图像,采样器决定了这一过程的轨迹与效率。关键参数包括:
seed:初始化噪声分布的随机种子。steps:去噪迭代的总步数,步数越多细节越丰富,但计算成本线性增加。cfg(Classifier-Free Guidance):控制生成图像对文本提示词的遵循程度。denoise:去噪强度,决定初始噪声的覆盖比例(在图生图任务中尤为重要)。
2. 图像生成管线
标准的文生图工作流通常遵循"文本编码 -> 潜在空间采样 -> 像素空间解码"的链路。以下为典型的工作流拓扑结构:
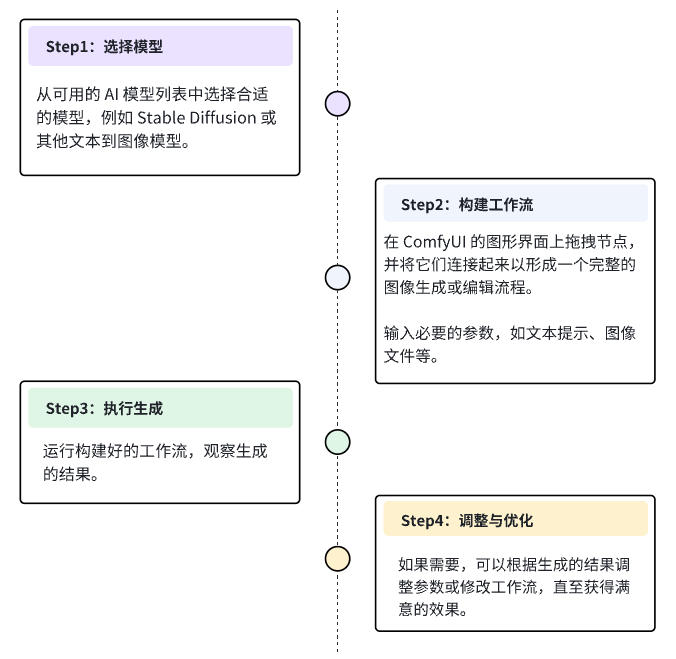
3. 环境部署与模型加载
在实际工程中,部署 ComfyUI 并集成自定义微调权重可以通过以下自动化脚本完成。该脚本优化了目录结构,并实现了环境依赖的自动同步:
# 初始化 Git LFS 并获取环境依赖
git lfs install
REPO_URL="https://www.modelscope.cn/datasets/maochase/kolors_test_comfyui.git"
TEMP_DIR="temp_comfyui_env"
git clone $REPO_URL $TEMP_DIR
rsync -av $TEMP_DIR/ ./
rm -rf $TEMP_DIR
# 配置微调后的 LoRA 权重路径
CKPT_DIR="/workspace/checkpoints/lora_weights/v1"
mkdir -p $CKPT_DIR
cp epoch=0-step=500.ckpt $CKPT_DIR/
环境就绪后,只需将对应的工作流 JSON 脚本导入 ComfyUI 界面,并指向上述配置好的模型路径,即可触发推理任务。
LoRA 参数高效微调机制
1. 算法原理
低秩自适应(Low-Rank Adaptation, LoRA)是一种参数高效微调(PEFT)策略。其核心思想是冻结预训练模型的主干权重,通过在特定网络层(如 Attention 层的 Q、V 投影矩阵)注入可训练的低秩分解矩阵来模拟权重更新。这种方法在保持模型泛化能力的同时,将显存占用和训练时间降低了数个数量级。
2. 训练工程实践
以下代码展示了如何使用 Python 的 subprocess 模块结构化地调用 LoRA 训练脚本。相比于直接拼接字符串,列表化传参能有效避免路径中包含空格导致的解析错误,并提升了代码的可维护性。
import subprocess
def execute_lora_training():
training_script = "DiffSynth-Studio/examples/train/kolors/train_kolors_lora.py"
# 结构化配置训练超参数
config_args = [
"--pretrained_unet_path", "assets/kolors/unet/diffusion_pytorch_model.safetensors",
"--pretrained_text_encoder_path", "assets/kolors/text_encoder",
"--pretrained_fp16_vae_path", "assets/sdxl-vae-fp16-fix/diffusion_pytorch_model.safetensors",
"--lora_rank", "32", # 提升秩以增强复杂特征拟合能力
"--lora_alpha", "8.0", # 缩放系数,通常设置为 rank 的倍数
"--dataset_path", "datasets/processed_images",
"--output_path", "./output_models",
"--max_epochs", "2",
"--center_crop", # 强制中心裁剪以统一输入分辨率
"--use_gradient_checkpointing", # 启用梯度检查点,以时间换空间
"--precision", "16-mixed" # 采用 FP16 混合精度加速计算
]
command = ["python", training_script] + config_args
subprocess.run(command, check=True)
if __name__ == "__main__":
execute_lora_training()
核心超参数映射表
| 参数标识 | 示例值 | 工程意义 |
|---|---|---|
pretrained_unet_path |
assets/.../unet.safetensors | 指定扩散模型主干权重的本地或远程路径。 |
lora_rank |
32 | 低秩矩阵的秩。值越大,模型容量越高,但显存消耗也随之增加。 |
lora_alpha |
8.0 | 缩放因子,与 rank 结合决定 LoRA 权重在推理时的合并比例(scaling = alpha / rank)。 |
precision |
"16-mixed" | 启用自动混合精度(AMP),在防止梯度溢出的同时大幅提升吞吐量。 |
3. 扩散模型核心组件协同机制
- 文本编码器(Text Encoder):作为条件注入的源头,利用 CLIP 架构将离散的文本 Token 转化为连续的语义向量,为后续去噪过程提供全局上下文指导。
- 变分自编码器(VAE):充当像素空间与潜在空间(Latent Space)的桥梁。编码器(Encoder)将高分辨率图像压缩为低维潜在特征,解码器(Decoder)则在生成末期将去噪后的潜在特征还原为像素图像,极大降低了计算复杂度。
- UNet 架构:扩散模型的"大脑"。它接收带有时间步信息的噪声潜在特征以及文本条件向量,通过交叉注意力机制(Cross-Attention)融合多模态信息,预测并剔除当前步的噪声残差。
训练数据集构建策略
高质量的领域数据集是 LoRA 微调成功的关键。以下是构建训练数据的常见途径:
| 构建策略 | 技术细节与适用场景 |
|---|---|
| 开源数据仓库 | 利用 Hugging Face、ModelScope 等主流社区提供的多模态数据集。可通过标签过滤快速筛选特定领域(如医学、遥感、特定艺术风格)的图像-文本对。 |
| 自动化采集 | 通过调用 Unsplash/Pexels 等免版权图库 API,或编写分布式爬虫定向抓取目标网站数据。需配合图像去重(如感知哈希算法)和自动化打标(如 BLIP-2)进行清洗。 |
| 合成数据生成 | 借助 Unreal Engine、Unity 等 3D 引擎渲染特定场景,或使用强大的基础大模型生成高质量先验数据,以解决长尾分布问题。 |
| 数据增强(Data Augmentation) | 在样本量受限时,应用随机裁剪、色彩抖动、仿射变换等传统 CV 技术,或基于 CutMix/MixUp 等高级策略扩充数据多样性,防止模型过拟合。 |
