基于TensorFlow实现WaveNet的音频生成实践
使用TensorFlow-WaveNet进行深度学习音频生成的详细步骤
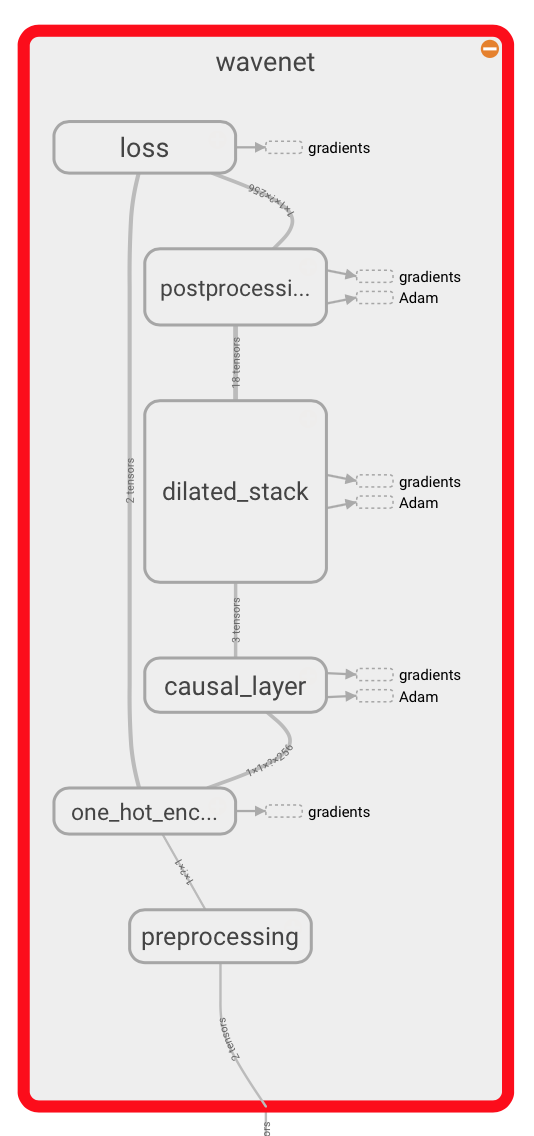
WaveNet简介
WaveNet是一种由DeepMind开发的生成式神经网络,能够通过建模原始音频波形生成高度逼真的声音。与传统方法不同,WaveNet直接从原始音频信号中学习概率分布,从而生成自然流畅的音频。
以下是WaveNet的核心特点:
- 高保真音频生成:适用于语音合成和音乐创作。
- 因果卷积架构:确保未来样本不会影响当前预测。
- 条件控制:支持多说话人模拟或特定风格生成。
环境搭建
系统要求
- Python 2.7 或 3.5+
- TensorFlow 1.0.1(CPU/GPU版本)
- librosa 音频处理库
安装步骤
- 克隆项目仓库:
git clone https://gitcode.com/gh_mirrors/te/tensorflow-wavenet
cd tensorflow-wavenet
- 安装依赖项:
- CPU版本:
pip install -r requirements.txt
- GPU版本(推荐):
pip install -r requirements_gpu.txt
参数配置
模型参数位于wavenet_params.json文件中,关键参数包括:
sample_rate: 采样率,默认16kHz。dilations: 扩张卷积层数列表。residual_channels: 残差通道数。quantization_channels: 音频量化级别,默认256。
训练过程
数据准备
训练数据需为.wav格式音频文件,建议使用VCTK语料库(约10GB)。将所有音频文件放置在同一目录下。
启动训练
运行以下命令开始训练:
python train.py --data_dir=<音频路径>
查看帮助选项:
python train.py --help
高级功能:全局条件控制
若需支持多说话人模拟,可启用全局条件:
python train.py --data_dir=<音频路径> --gc_channels=32
--gc_channels定义嵌入向量维度,用于区分不同说话人。
音频生成
基础生成
使用预训练模型生成音频:
python generate.py --samples 16000 <模型路径>
输出为WAV文件
保存生成的音频为WAV格式:
python generate.py --wav_out_path=output.wav --samples 16000 <模型路径>
快速生成模式
默认启用快速生成模式以加速处理:
python generate.py --samples 16000 <模型路径> --fast_generation=true
条件生成
指定说话人ID生成特定风格音频:
python generate.py --wav_out_path=speaker_output.wav --gc_channels=32 --gc_cardinality=377 --gc_id=311 <模型路径>
测试与验证
安装测试依赖:
pip install -r requirements_test.txt
运行测试脚本:
./ci/test.sh
核心代码示例
以下是生成音频的简化代码逻辑:
import tensorflow as tf
from wavenet import model, audio_reader
# 加载模型配置
config = model.load_config("wavenet_params.json")
# 初始化模型
generator = model.WaveNetModel(config)
# 设置生成参数
num_samples = 16000
output_file = "generated_audio.wav"
# 开始生成
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
generator.restore(sess, "path/to/checkpoint")
waveform = generator.generate(num_samples)
audio_reader.save_wav(waveform, output_file)
项目结构
主要文件及功能如下:
wavenet/model.py: 网络模型定义。train.py: 训练脚本。generate.py: 音频生成脚本。wavenet/audio_reader.py: 音频读取与预处理。wavenet/ops.py: 自定义TensorFlow操作。
常见问题
- 训练速度慢:检查是否启用了GPU加速。
- 内存不足:降低批量大小或减少模型复杂度。
- 生成质量低:增加训练步数或扩展数据集规模。
通过以上步骤,您可以轻松上手TensorFlow-WaveNet,并探索其在音频生成领域的潜力。
