基于PySpark与Echarts的二手房数据全链路可视化系统
项目背景与核心目标
在房地产市场日益数据化的今天,如何高效处理海量房源信息并以直观方式呈现分析结果,成为决策支持的关键。本项目围绕广西地区二手房挂牌数据,构建了一套完整的数据处理与可视化流程,涵盖从原始数据采集、分布式清洗统计,到数据库持久化、后端API服务及前端大屏展示的全流程。
系统主要实现以下目标:
- 利用PySpark对大规模非结构化/半结构化数据进行高性能清洗与聚合分析;
- 将统计结果写入MySQL供后续查询调用;
- 通过Django框架提供REST风格接口,动态生成可视化配置数据;
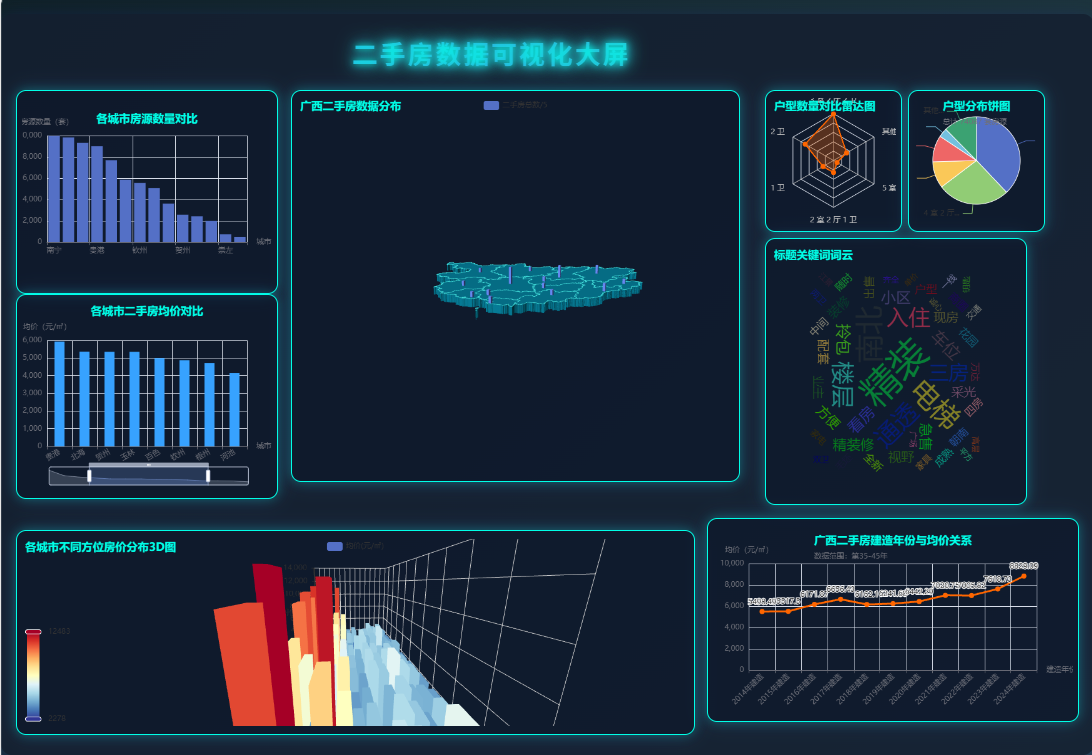
- 前端采用Echarts生态实现多维度图表渲染,包括3D地理分布图、词云、柱状图、折线趋势等;
- 支持深色主题、弹性布局、卡片式UI设计,适配大屏展示场景。
技术架构与环境准备
系统采用分层架构设计,各模块职责明确,便于维护和扩展。
技术栈选型
| 组件 | 用途 |
|---|---|
| Python 3.8+ | 核心开发语言 |
| PySpark 3.x | 分布式数据处理引擎 |
| MySQL 8.0 | 结构化结果存储 |
| Django 4.x | Web服务与API网关 |
| Pyecharts 2.0 | 图表Option生成工具 |
| Echarts 5.4 + GL | 前端可视化渲染库 |
| HDFS | 原始数据集中存储 |
依赖安装
# Python环境依赖
pip install pyspark django pymysql pyecharts jieba
# 前端CDN资源引入(HTML中)
<script src="https://cdn.jsdelivr.net/npm/echarts@5.4.3/dist/echarts.min.js"></script>
<script src="https://cdn.jsdelivr.net/npm/echarts-gl@2.0.9/dist/echarts-gl.min.js"></script>
<script src="https://cdn.jsdelivr.net/npm/echarts-wordcloud@2.0.0/dist/echarts-wordcloud.min.js"></script>
运行环境要求
- JDK 1.8+ 并配置 JAVA_HOME
- Spark集群或本地模式部署完成
- MySQL创建名为
ershoufang的数据库 - Hadoop HDFS 启动并可访问指定路径
数据来源与预处理
原始数据由自研爬虫程序从主流房产平台抓取,覆盖南宁、柳州、桂林等广西主要城市,字段包含户型、总价、均价、建造年份、朝向、标题关键词等。
数据获取方式
爬虫代码托管于GitHub:
https://github.com/weijiayi-1/anjuke-crawler采集过程使用requests结合Selenium模拟浏览器行为,应对反爬机制,并将结果保存为CSV格式上传至HDFS:
hdfs dfs -put /local/data/ershoufang_cleaned.csv /data/
字段说明
| 字段名 | 描述 | 示例值 |
|---|---|---|
| city | 所在城市 | 南宁 |
| huxing | 房屋格局 | 三室两厅 |
| total_price | 总售价(万元) | 135 |
| unit_price | 单价(元/㎡) | 9200 |
| build_year | 建筑年份 | 2010 |
| orientation | 房屋朝向 | 南 |
| title_desc | 房源描述标题 | 学区房 精装修 满五唯一 |
Spark读取HDFS数据
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("SecondHandHouseAnalysis") \
.getOrCreate()
# 从HDFS加载已清洗的数据
raw_df = spark.read.option("header", "true").csv("hdfs:///data/ershoufang_cleaned.csv")
cleaned_df = raw_df.dropna() # 移除空值记录
PySpark数据清洗与统计计算
多个独立脚本分别执行不同维度的统计任务,最终结果统一写入MySQL。
初始化Spark会话
from pyspark.sql import SparkSession, functions as F
from pyspark.sql.types import *
conf = SparkSession.builder \
.master("spark://192.168.126.10:7077") \
.config("spark.driver.host", "192.168.126.1") \
.appName("CityHouseStats") \
.getOrCreate()
统计任务实现
城市房源数量分布
city_stats = cleaned_df.groupBy("city") \
.agg(F.count("*").alias("listing_count")) \
.orderBy(F.desc("listing_count"))
按方位与城市计算平均单价
location_price = cleaned_df.filter(cleaned_df.unit_price.isNotNull()) \
.groupBy("orientation", "city") \
.agg(F.round(F.avg("unit_price"), 2).alias("avg_unit_price")) \
.orderBy("orientation", "city")
热门户型TOP5合并其余为"其他"
top_layouts = cleaned_df.groupBy("huxing") \
.count() \
.orderBy(F.desc("count")) \
.limit(5)
other_count = cleaned_df.subtract(top_layouts.rdd.map(lambda r: r.huxing).collect()) \
.count()
# 构造"其他"类别并合并
other_row = [(F.lit("其他户型"), other_count)]
other_df = spark.createDataFrame(other_row, ["huxing", "count"])
final_layout_dist = top_layouts.unionByName(other_df)
标题关键词提取与频率统计
import jieba
from pyspark.sql.functions import udf, explode
from pyspark.sql.types import ArrayType, StringType
# 中文分词UDF
def segment(text):
if not text:
return []
stopwords = {"的", "了", "和", "是", "有"}
return [word for word in jieba.lcut(text) if len(word) > 1 and word not in stopwords]
segment_udf = udf(segment, ArrayType(StringType()))
# 分词后展开统计频次
words_df = cleaned_df.select(explode(segment_udf(F.col("title_desc"))).alias("keyword"))
keyword_freq = words_df.groupBy("keyword") \
.count() \
.orderBy(F.desc("count")) \
.limit(50)
按建造年代区间分析均价趋势
from pyspark.sql.window import Window
yearly_avg = cleaned_df.groupBy("build_year") \
.agg(F.round(F.avg("unit_price"), 2).alias("mean_price"))
# 添加行号筛选特定时间段(如第35-45条)
window_spec = Window.orderBy("build_year")
ranked_data = yearly_avg.withColumn("row_index", F.row_number().over(window_spec))
subset_data = ranked_data.filter((F.col("row_index") >= 35) & (F.col("row_index") <= 45)) \
.drop("row_index")
结果写入MySQL
def save_to_mysql(df, table_name):
jdbc_url = "jdbc:mysql://192.168.126.10:3306/ershoufang"
props = {
"user": "root",
"password": "123456",
"driver": "com.mysql.cj.jdbc.Driver"
}
df.coalesce(1).write.jdbc(url=jdbc_url, table=table_name, mode="overwrite", properties=props)
# 示例调用
save_to_mysql(city_stats, "city_listing_summary")
Django后端服务开发
后端负责连接数据库、生成图表配置项并通过HTTP接口对外提供数据。
项目结构
visual_screen/
├── charts/
│ ├── views.py
│ ├── urls.py
│ └── templates/charts/chart.html
└── settings.py
数据库查询与图表生成
import pymysql
from pyecharts.charts import Bar, Pie, WordCloud, Map3D
from pyecharts import options as opts
def fetch_city_counts():
conn = pymysql.connect(
host='192.168.126.10',
user='root', password='123456',
database='ershoufang', charset='utf8mb4'
)
with conn.cursor() as cur:
cur.execute("SELECT city, listing_count FROM city_listing_summary ORDER BY listing_count DESC")
rows = cur.fetchall()
conn.close()
return [r[0] for r in rows], [int(r[1]) for r in rows]
def build_bar_chart():
cities, counts = fetch_city_counts()
bar = (
Bar()
.add_xaxis(cities)
.add_yaxis("挂牌量", counts, category_gap="50%")
.set_global_opts(
title_opts=opts.TitleOpts(title="各城市二手房挂牌数量"),
tooltip_opts=opts.TooltipOpts(is_show=True),
legend_opts=opts.LegendOpts(pos_left="center")
)
)
return bar
API接口定义
from django.http import JsonResponse
def get_all_charts(request):
try:
bar_opt = build_bar_chart().dump_options()
pie_opt = build_pie_chart().dump_options()
wordcloud_opt = build_wordcloud().dump_options()
map3d_opt = build_3d_map().dump_options()
return JsonResponse({
"status": "success",
"data": {
"bar": bar_opt,
"pie": pie_opt,
"wordcloud": wordcloud_opt,
"map3d": map3d_opt
}
})
except Exception as e:
# 异常时返回默认选项防止前端崩溃
return JsonResponse({"status": "error", "message": str(e)}, status=500)
前端大屏可视化实现
前端页面通过Ajax请求获取JSON格式的图表配置,并交由Echarts实例化渲染。
图表动态加载
fetch("/charts/data/")
.then(res => res.json())
.then(result => {
if (result.status === "success") {
const data = result.data;
echarts.init(document.getElementById("barContainer")).setOption(JSON.parse(data.bar));
echarts.init(document.getElementById("pieContainer")).setOption(JSON.parse(data.pie));
echarts.init(document.getElementById("wordcloudContainer")).setOption(JSON.parse(data.wordcloud));
initMap3D(data.map3d); // 特殊处理3D地图
}
});
3D地图初始化
function initMap3D(mapOpt) {
fetch("https://geo.datav.aliyun.com/areas_v3/bound/450000_full.json")
.then(resp => resp.json())
.then(geoJson => {
echarts.registerMap("Guangxi", geoJson);
const chart = echarts.init(document.getElementById("map3dContainer"));
chart.setOption(JSON.parse(mapOpt));
});
}
页面布局与视觉优化
- 采用CSS Flex布局划分左、中、右三大区域及底部栏;
- 整体使用暗黑主题提升视觉对比度;
- 卡片容器添加阴影与圆角边框增强层次感;
- 主标题使用渐变字体与动画效果突出重点;
- 所有图表容器设置固定宽高比例,确保响应一致性。
常见问题排查与优化建议
词云无法显示
- 确认已正确引入
echarts-wordcloud.min.js插件; - 检查后端返回的词频数值是否过大,建议做归一化处理;
- 避免出现单个词语占比过高导致其他词汇不可见。
3D地图不渲染
- 验证GeoJSON是否成功注册地图名称;
- 确保DOM容器具备足够尺寸(建议最小400x300px);
- 检查浏览器是否支持WebGL。
图表排版错乱
- 统一设置字体大小与颜色主题;
- 合理调整margin/padding避免重叠;
- 使用媒体查询适配不同分辨率屏幕。
总结与未来扩展方向
本项目实现了从原始数据采集到终端可视化的完整闭环,展示了大数据分析在房地产领域的典型应用。系统具备良好的可扩展性,后续可进一步增强如下能力:
- 接入Kafka实现实时数据流处理,支持动态刷新;
- 增加用户交互功能,如城市筛选、价格区间过滤、图表联动;
- 支持移动端适配,实现跨平台访问;
- 集成机器学习模型预测房价走势。