基于UNet++的舌象分割实践指南
本文聚焦于医学图像分割任务,采用UNet++网络架构实现舌象分割。UNet++是U-Net的改进版本,通过嵌套密集跳跃连接和深度监督机制,有效缩小编码器与解码器特征图间的语义差异,提升模型对精细结构的捕捉能力。
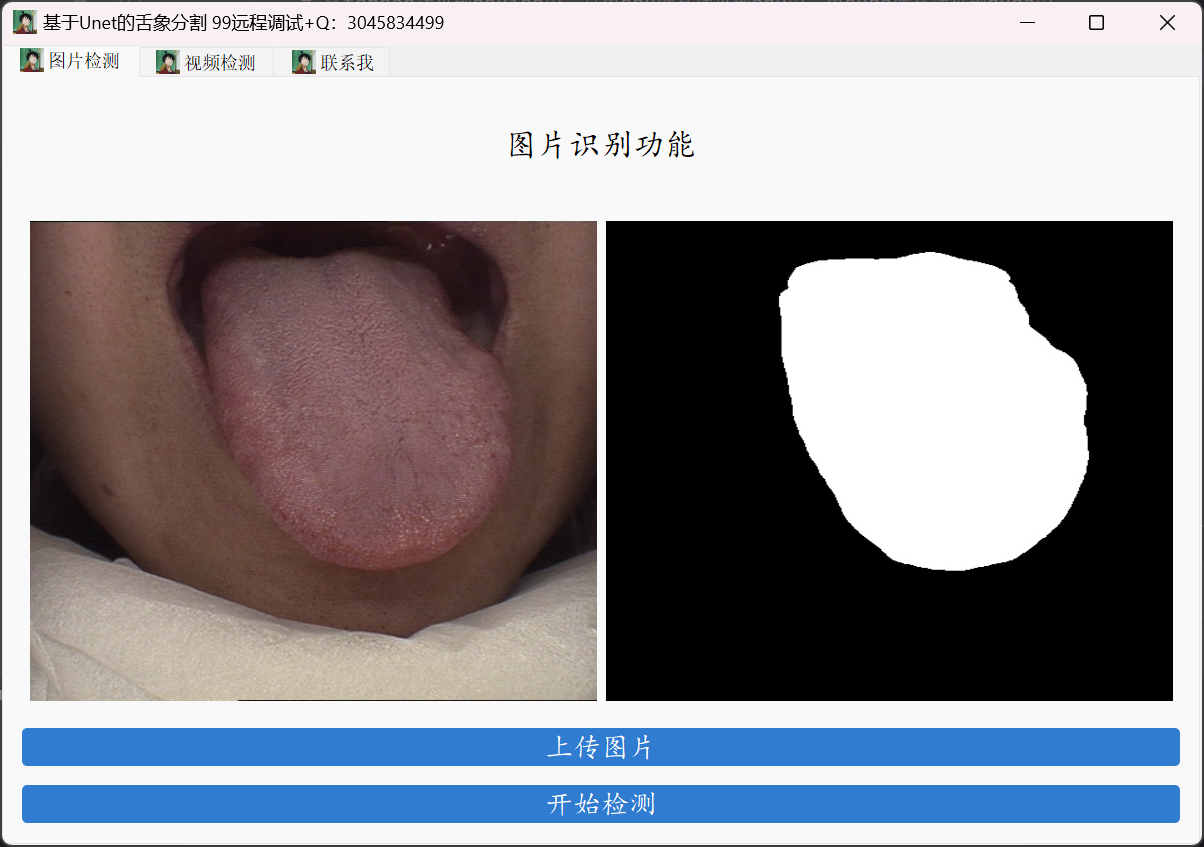
1. 效果展示
运行训练好的模型,可对输入图片或视频中的舌象进行精准分割。下图展示了分割前后对比结果:
2. UNet++网络结构解析
2.1 设计思想
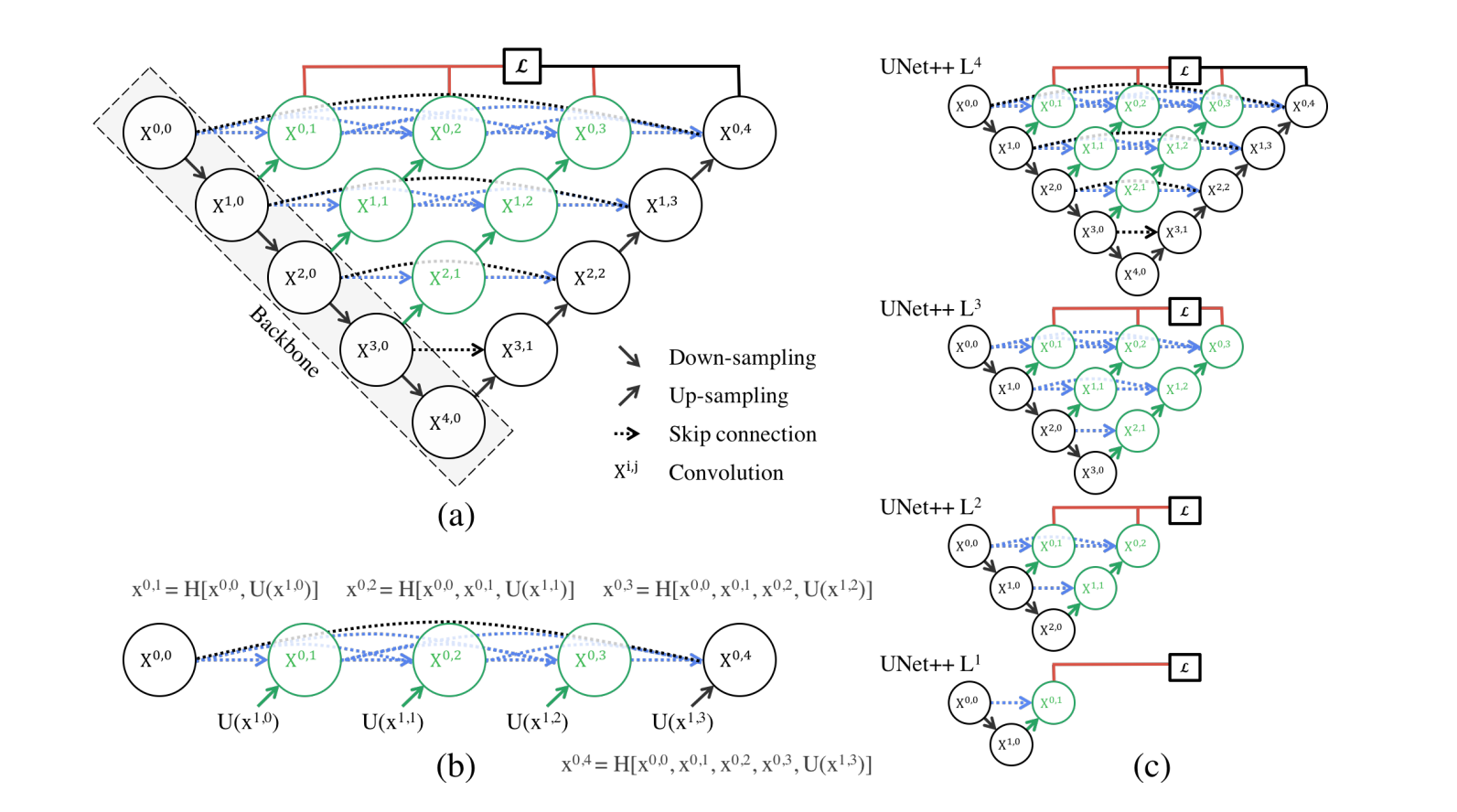
UNet++的核心在于重新设计跳跃连接路径,用密集连接替代传统U-Net的单次跳跃。每个解码器层接收来自多个编码器层的特征,通过叠加融合多尺度信息。这种结构使网络同时具备大感受野(捕捉全局信息)和小感受野(保留细节边缘)的能力,特别适合处理大小不一的病灶区域。
训练时,网络输出四个不同深度的预测图(深度监督模式),分别计算损失;推理时则进行剪枝,仅保留最优分支,降低参数量。
2.2 网络结构图
3. 环境配置与数据准备
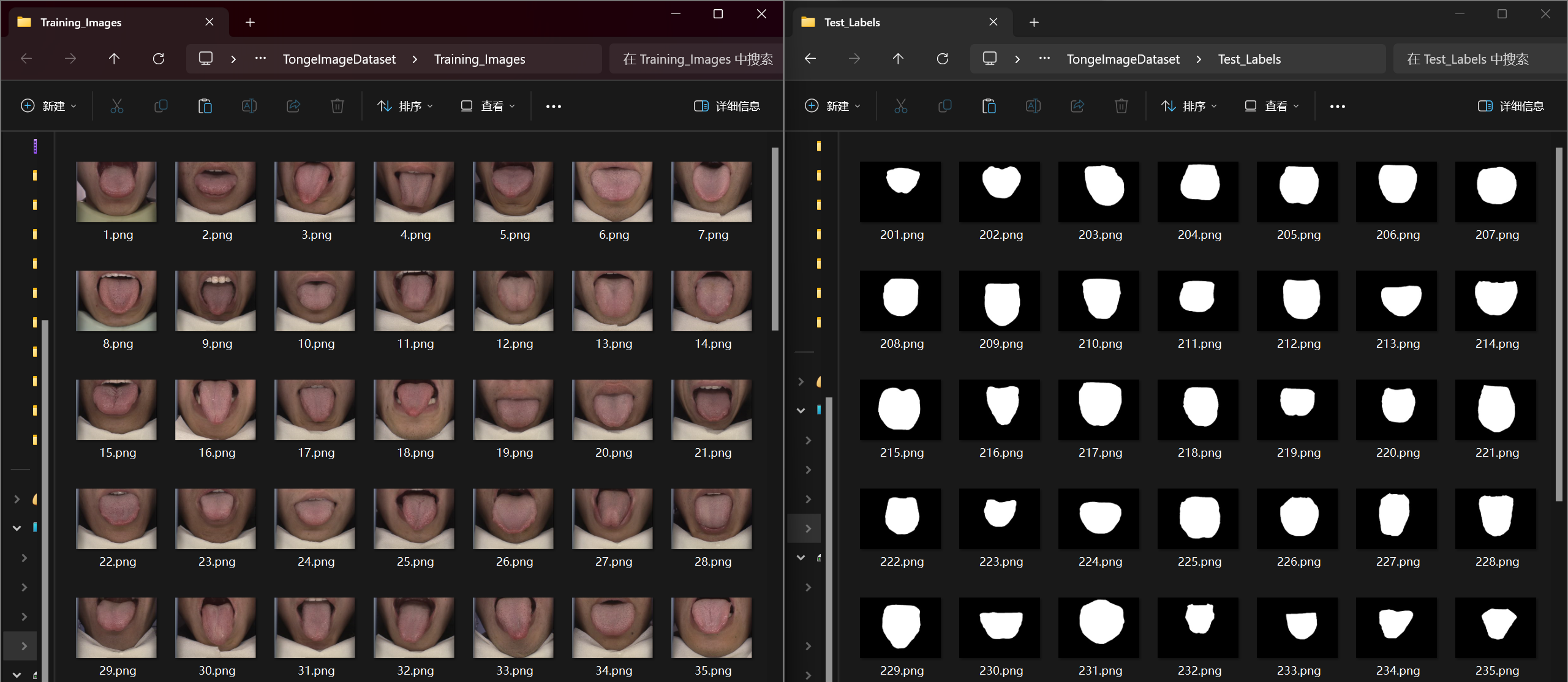
3.1 数据集
采用二分类舌象分割数据集,原始图片为PNG彩色图像,标签为黑白掩码(PNG格式)。
3.2 环境搭建
配置Anaconda和PyCharm后,执行以下命令:
# 配置镜像加速
conda config --remove-key channels
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.bfsu.edu.cn/anaconda/cloud/pytorch/
conda config --set show_channel_urls yes
pip config set global.index-url https://mirrors.ustc.edu.cn/pypi/simple
# 创建虚拟环境
conda create -n unetpp python==3.8.5
conda activate unetpp
# 安装PyTorch(根据硬件选其一)
conda install pytorch==1.8.0 torchvision torchaudio cudatoolkit=10.2
conda install pytorch==1.10.0 torchvision torchaudio cudatoolkit=11.3
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cpuonly
# 安装其他依赖
pip install -r requirements.txt在PyCharm中加载虚拟环境,运行unetpp_step4_window.py测试配置。
4. 核心代码实现
4.1 网络结构(PyTorch实现)
import torch
from torch import nn
from torch.nn import functional as F
class DoubleConv(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, 3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.conv(x)
class UNetPlusPlus(nn.Module):
def __init__(self, in_ch=1, out_ch=1, deep_supervision=True):
super().__init__()
self.deep_supervision = deep_supervision
filters = [32, 64, 128, 256, 512]
self.pool = nn.MaxPool2d(2, 2)
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
# 编码器
self.conv0_0 = DoubleConv(in_ch, filters[0])
self.conv1_0 = DoubleConv(filters[0], filters[1])
self.conv2_0 = DoubleConv(filters[1], filters[2])
self.conv3_0 = DoubleConv(filters[2], filters[3])
self.conv4_0 = DoubleConv(filters[3], filters[4])
# 嵌套密集连接层
self.conv0_1 = DoubleConv(filters[0] + filters[1], filters[0])
self.conv1_1 = DoubleConv(filters[1] + filters[2], filters[1])
self.conv2_1 = DoubleConv(filters[2] + filters[3], filters[2])
self.conv3_1 = DoubleConv(filters[3] + filters[4], filters[3])
self.conv0_2 = DoubleConv(filters[0]*2 + filters[1], filters[0])
self.conv1_2 = DoubleConv(filters[1]*2 + filters[2], filters[1])
self.conv2_2 = DoubleConv(filters[2]*2 + filters[3], filters[2])
self.conv0_3 = DoubleConv(filters[0]*3 + filters[1], filters[0])
self.conv1_3 = DoubleConv(filters[1]*3 + filters[2], filters[1])
self.conv0_4 = DoubleConv(filters[0]*4 + filters[1], filters[0])
# 输出层
self.sigmoid = nn.Sigmoid()
if deep_supervision:
self.out1 = nn.Conv2d(filters[0], out_ch, 1)
self.out2 = nn.Conv2d(filters[0], out_ch, 1)
self.out3 = nn.Conv2d(filters[0], out_ch, 1)
self.out4 = nn.Conv2d(filters[0], out_ch, 1)
else:
self.out = nn.Conv2d(filters[0], out_ch, 1)
def forward(self, x):
x0_0 = self.conv0_0(x)
x1_0 = self.conv1_0(self.pool(x0_0))
x0_1 = self.conv0_1(torch.cat([x0_0, self.up(x1_0)], dim=1))
x2_0 = self.conv2_0(self.pool(x1_0))
x1_1 = self.conv1_1(torch.cat([x1_0, self.up(x2_0)], dim=1))
x0_2 = self.conv0_2(torch.cat([x0_0, x0_1, self.up(x1_1)], dim=1))
x3_0 = self.conv3_0(self.pool(x2_0))
x2_1 = self.conv2_1(torch.cat([x2_0, self.up(x3_0)], dim=1))
x1_2 = self.conv1_2(torch.cat([x1_0, x1_1, self.up(x2_1)], dim=1))
x0_3 = self.conv0_3(torch.cat([x0_0, x0_1, x0_2, self.up(x1_2)], dim=1))
x4_0 = self.conv4_0(self.pool(x3_0))
x3_1 = self.conv3_1(torch.cat([x3_0, self.up(x4_0)], dim=1))
x2_2 = self.conv2_2(torch.cat([x2_0, x2_1, self.up(x3_1)], dim=1))
x1_3 = self.conv1_3(torch.cat([x1_0, x1_1, x1_2, self.up(x2_2)], dim=1))
x0_4 = self.conv0_4(torch.cat([x0_0, x0_1, x0_2, x0_3, self.up(x1_3)], dim=1))
if self.deep_supervision:
o1 = self.sigmoid(self.out1(x0_1))
o2 = self.sigmoid(self.out2(x0_2))
o3 = self.sigmoid(self.out3(x0_3))
o4 = self.sigmoid(self.out4(x0_4))
return [o1, o2, o3, o4]
else:
return self.sigmoid(self.out(x0_4))4.2 训练流程
训练脚本unetpp_step1_train.py核心逻辑:
if __name__ == "__main__":
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
net = UNetPlusPlus(1, 1, deep_supervision=True).train()
net.to(device)
data_root = "../TongeImageDataset"
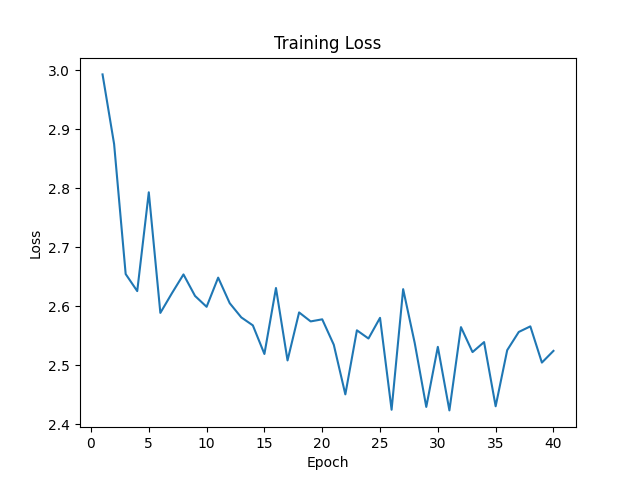
train_net(net, device, data_root, epochs=40, batch_size=1)训练过程损失下降曲线:
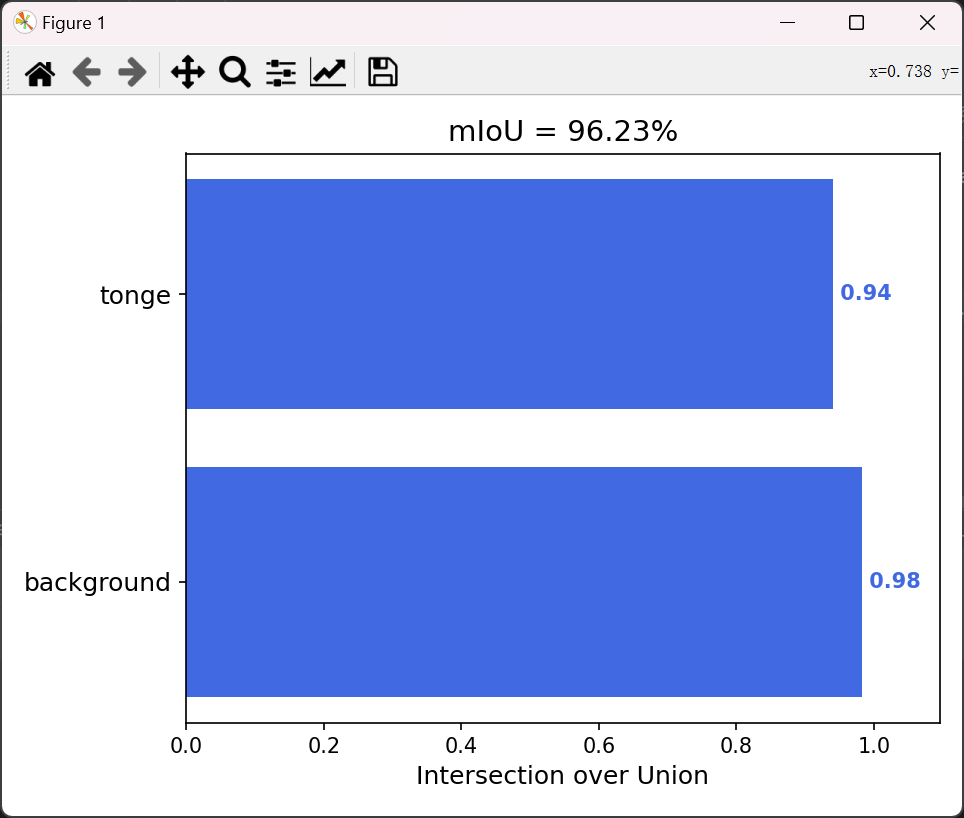
4.3 测试与指标计算
运行unetpp_step2_test.py评估模型:
cal_miou(test_dir="../TongeImageDataset/Test_Images",
pred_dir="../TongeImageDataset/results",
gt_dir="../TongeImageDataset/Test_Labels",
model_path='best_model_unetpp.pth')4.4 图形化界面
基于PyQt5开发界面,支持图片和视频检测。视频检测通过分帧处理并采用多线程避免界面卡顿: