LlamaIndex存储架构核心解析
存储系统概览
LlamaIndex的存储架构由多个可插拔模块构成,分别管理特定类型的数据组件。这些模块共同为语言模型提供结构化数据底座:
- 文档存储(Document Store)
- 索引存储(Index Store)
- 向量存储(Vector Store)
- 属性图存储(Property Graph Store)
- 聊天记录存储(Chat Message Store)
通过统一的StorageContext进行集中管理,支持从内存存储到分布式数据库的灵活扩展。
LlamaIndex存储架构总览
┌───────────────────────┐
│ 原始数据 │
│ (PDF/HTML/DB/API等) │
└───────────┬───────────┘
│
▼
┌─────────────────────┐
│ 文档加载器 │
└───────────┬─────────┘
│
▼
┌─────────────────┐
│ 节点解析器 │
└─────────┬───────┘
│
▼
┌──────────────┐
│ 文本节点 │
│ (内容+元数据) │
└───────┬──────┘
│
┌─────────────┴───────────────┐
│ StorageContext │
│ (统一管理存储组件) │
└─────────────┬───────────────┘
│
┌───────────────────────────┼─────────────────────────┐
▼ ▼ ▼
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ 文档存储 │ │ 索引存储 │ │ 向量存储 │
│ (节点管理) │ │ (元数据记录) │ │ (嵌入检索) │
└─────────────┘ └─────────────┘ └─────────────┘
│
▼
┌───────────────┐
│ 图存储 │
│ (知识图谱) │
└───────────────┘
│
▼
┌─────────────┐
│ 聊天存储 │
│ (会话记录) │
└─────────────┘
核心存储组件解析
文档存储(Document Store)
管理文档解析后生成的文本节点(Node),每个节点包含:
- 文本内容片段
- 元信息(来源/页码等)
- 向量嵌入(索引构建后注入)
from llama_index.core import Document
from llama_index.storage.docstore import SimpleDocumentStore
from llama_index.core.node_parser import TokenTextSplitter
data_docs = Document.load_from_dir("dataset")
text_splitter = TokenTextSplitter()
text_nodes = text_splitter.process_docs(data_docs)
node_storage = SimpleDocumentStore()
for node in text_nodes:
node_storage.add_node(node)
storage_ctx = StorageContext(doc_store=node_storage)
索引存储(Index Store)
维护索引结构元数据,支持索引快速恢复:
- 向量索引的倒排表
- 树形索引的层级关系
- 查询配置参数
from llama_index.storage.index_store import RedisIndexStore
from llama_index.core import VectorStoreIndex
idx_storage = RedisIndexStore(host="localhost")
storage_ctx = StorageContext(index_store=idx_storage)
vector_index = VectorStoreIndex(text_nodes, storage_context=storage_ctx)
storage_ctx.persist("./index_data")
向量存储(Vector Store)
存储文本嵌入并提供相似性检索:
| 解决方案 | 特性 |
|---|---|
| FAISS | 单机高性能 |
| Chroma | 轻量易集成 |
| Milvus | 分布式架构 |
| Qdrant | Rust高性能 |
| Pinecone | 云托管服务 |
from llama_index.vector_stores.pinecone import PineconeVectorStore
from llama_index.core import VectorStoreIndex
vector_db = PineconeVectorStore(index_name="tech_docs")
storage_ctx = StorageContext(vector_store=vector_db)
search_index = VectorStoreIndex(text_nodes, storage_context=storage_ctx)
result = search_index.as_query_engine().query("存储架构核心组件?")
print(result.response)
属性图存储(Property Graph Store)
管理知识图谱结构数据:
- 实体与关系
- 属性键值对
from llama_index.graph_stores.neo4j import Neo4jGraphStore
from llama_index.indices.property_graph import KnowledgeGraphIndex
graph_db = Neo4jGraphStore(uri="bolt://localhost", username="neo4j")
kg_index = KnowledgeGraphIndex.from_docs(
data_docs,
property_graph_store=graph_db
)
connections = kg_index.fetch_relations("向量存储")
print(connections)
聊天记录存储(Chat Message Store)
持久化多轮对话上下文:
- 会话线程管理
- 历史消息存储
- 长期记忆支持
from llama_index.storage.chat_store import MongoDBMessageStore
from llama_index.core.memory import ConversationBuffer
chat_history = MongoDBMessageStore(collection="dialogs")
memory = ConversationBuffer(
token_capacity=4096,
chat_store=chat_history
)
memory.record("user", "解释图存储作用")
memory.record("assistant", "图存储管理实体关系...")
print(memory.get_recent(3))
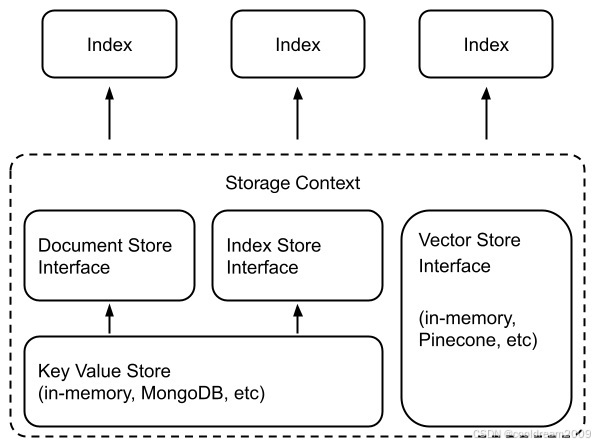
存储组件协同工作机制
组件通过StorageContext实现数据联动:
- 文档解析节点存入DocumentStore
- 向量嵌入写入VectorStore
- 索引元数据保存至IndexStore
- 图结构持久化到GraphStore
- 对话记录存储于ChatStore
实践示例:端到端流程
# 初始化存储上下文
storage_ctx = StorageContext()
# 创建向量索引
main_index = VectorStoreIndex.from_documents(
data_docs,
storage_context=storage_ctx
)
# 持久化存储
storage_ctx.persist("./storage_db")
# 恢复索引
from llama_index.core import load_index_from_storage
loaded_index = load_index_from_storage(storage_ctx)
# 执行查询
query_result = loaded_index.as_query_engine().query("存储持久化方法?")
print(query_result)
