Cocos2d-x渲染批处理命令详解:BatchCommand
在Cocos2d-x的渲染架构中,为了提升绘制效率,引入了多种渲染命令。上一篇我们探讨了QUAD_COMMAND等基础命令的处理,并简要介绍了VAO和VBO。本篇文章将深入解析Cocos2d-x中的批处理渲染命令BatchCommand,它在渲染器(Renderer)中的处理流程相对直接。
BatchCommand的渲染器处理
当渲染器遇到一个BatchCommand类型的命令时,其处理逻辑如下:
// 假设 renderer 为当前渲染器实例,renderCmd 为待处理的渲染命令
// ... 其他渲染命令处理分支 ...
else if (renderCmd->getType() == RenderCommand::Type::BATCH_COMMAND) {
// 在执行批处理命令之前,首先清空渲染队列中所有待绘制的命令
renderer->flush();
// 将通用渲染命令转换为具体的 BatchCommand 类型
auto* batchCommandInstance = static_cast(renderCmd);
// 调用批处理命令自身的执行函数
batchCommandInstance->execute();
}
// ...
可以看到,渲染器首先调用flush()方法,这会将之前所有缓存的渲染指令(如四边形、自定义绘制等)提交给GPU进行绘制。随后,它将当前的渲染命令强制转换为BatchCommand类型,并直接调用其execute()方法。这个流程与CUSTOM_COMMAND类似,但区别在于BatchCommand::execute()执行的是批处理命令预定义的绘制逻辑,而CUSTOM_COMMAND则执行一个传入的回调函数。
BatchCommand::execute()方法解析
BatchCommand的核心功能体现在其execute()方法中,该方法负责设置OpenGL状态并执行批次绘制:
void BatchCommand::execute() {
// 激活并使用当前的着色器程序
_shaderProgram->use();
// 设置着色器中内置的Uniform变量,特别是处理MVP矩阵
_shaderProgram->setUniformsForBuiltins(_modelViewMatrix);
// 绑定纹理到默认的纹理单元(GL_TEXTURE0)
GL::bindTexture2D(_textureID);
// 设置OpenGL的混合模式
GL::blendFunc(_blendFunc.src, _blendFunc.dst);
// 执行实际的四边形批次绘制
_textureAtlas->drawQuads();
}
该方法依次完成了着色器激活、MVP矩阵设置、纹理绑定、混合模式设置以及最终的四边形批次绘制。
MVP矩阵:图形变换的核心
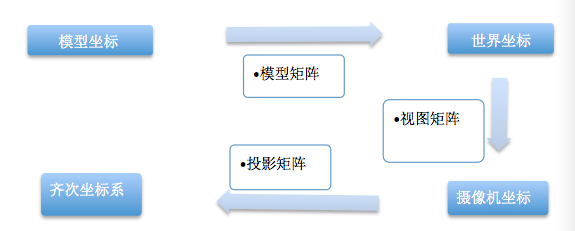
在BatchCommand::execute()中,_shaderProgram->setUniformsForBuiltins(_modelViewMatrix)这一步是图形渲染中至关重要的。它涉及到MVP,即模型(Model)、视图(View)、投影(Projection)三个矩阵的组合变换。
- 模型矩阵(Model Matrix): 将物体从其本地模型空间转换到全局世界空间。每个物体都有其独立的模型矩阵,用于定义其在世界中的位置、旋转和缩放。
- 视图矩阵(View Matrix): 将物体从世界空间转换到摄像机(或观察者)空间。它模拟了摄像机的位置和朝向,决定了我们"看到"场景的哪个部分。
- 投影矩阵(Projection Matrix): 将3D观察空间中的物体投影到2D屏幕平面。这通常分为透视投影(用于模拟真实世界的远近感)和正交投影(用于2D游戏或工程视图)。
这三个矩阵按顺序相乘(通常是 Projection * View * Model)得到最终的模型视图投影矩阵(MVP),用于将3D顶点坐标转换到屏幕上的2D坐标。整个变换过程如下图所示:
GLProgram::setUniformsForBuiltins()的实现细节
setUniformsForBuiltins函数负责将MVP矩阵以及其他一些内置的、常用的数据(如时间、随机数)传递给着色器程序。这里着重强调OpenGL中的uniform变量概念:uniform是一种全局的、只读的着色器变量,其值在一次绘制调用(或一系列绘制调用中的一个批次)中保持不变,常用于向着色器传递变换矩阵、光照参数、纹理ID等数据。
为了提高效率,Cocos2d-x的实现会进行优化,避免重复设置相同值的uniform。
void GLProgram::setUniformsForBuiltins(const kmMat4& modelViewMat) {
// 通过着色器程序的标志 (_flags) 判断是否需要更新特定的 uniform 变量
// 这些标志在着色器编译链接时根据着色器代码进行分析和设置
kmMat4 projectionMat;
// 获取当前OpenGL的投影矩阵
kmGLGetMatrix(KM_GL_PROJECTION, &projectionMat);
// 如果着色器需要投影矩阵 uniform
if (_flags.usesP) {
setUniformLocationWithMatrix4fv(_uniforms[UNIFORM_P_MATRIX], projectionMat.mat, 1);
}
// 如果着色器需要模型视图矩阵 uniform
if (_flags.usesMV) {
setUniformLocationWithMatrix4fv(_uniforms[UNIFORM_MV_MATRIX], modelViewMat.mat, 1);
}
// 如果着色器需要模型视图投影矩阵 uniform
if (_flags.usesMVP) {
kmMat4 mvpMat;
kmMat4Multiply(&mvpMat, &projectionMat, &modelViewMat); // P * MV
setUniformLocationWithMatrix4fv(_uniforms[UNIFORM_MVP_MATRIX], mvpMat.mat, 1);
}
// 处理时间相关的 uniform 变量,常用于动画或随时间变化的特效
if (_flags.usesTime) {
Director* director = Director::getInstance();
// 出于性能考虑,此处通常不使用精确到每帧的真实时间,而是使用帧计数和动画间隔计算的总时间
float totalTime = director->getTotalFrames() * director->getAnimationInterval();
setUniformLocationWith4f(_uniforms[GLProgram::UNIFORM_TIME], totalTime / 10.0f, totalTime, totalTime * 2.0f, totalTime * 4.0f);
setUniformLocationWith4f(_uniforms[GLProgram::UNIFORM_SIN_TIME], totalTime / 8.0f, totalTime / 4.0f, totalTime / 2.0f, sinf(totalTime));
setUniformLocationWith4f(_uniforms[GLProgram::UNIFORM_COS_TIME], totalTime / 8.0f, totalTime / 4.0f, totalTime / 2.0f, cosf(totalTime));
}
// 处理随机数相关的 uniform 变量
if (_flags.usesRandom) {
setUniformLocationWith4f(_uniforms[GLProgram::UNIFORM_RANDOM01], CCRANDOM_0_1(), CCRANDOM_0_1(), CCRANDOM_0_1(), CCRANDOM_0_1());
}
}
纹理绑定 GL::bindTexture2DN()
在批处理命令中,纹理绑定是另一个关键步骤。GL::bindTexture2DN()函数封装了OpenGL的纹理激活和绑定操作:
void GL::bindTexture2DN(GLuint textureUnit, GLuint textureId) {
#if CC_ENABLE_GL_STATE_CACHE
// 启用OpenGL状态缓存时,检查是否需要重新绑定
CCASSERT(textureUnit < kMaxActiveTexture, "Texture unit index is too large!");
if (s_currentBoundTexture[textureUnit] != textureId) {
s_currentBoundTexture[textureUnit] = textureId; // 更新缓存状态
glActiveTexture(GL_TEXTURE0 + textureUnit); // 激活指定的纹理单元
glBindTexture(GL_TEXTURE_2D, textureId); // 将纹理ID绑定到该纹理单元
}
#else
// 未启用状态缓存时,直接调用OpenGL函数
glActiveTexture(GL_TEXTURE0 + textureUnit);
glBindTexture(GL_TEXTURE_2D, textureId);
#endif
}
glActiveTexture(GL_TEXTURE0 + textureUnit)用于选择一个纹理单元,后续的纹理操作(如glBindTexture)将作用于该单元。glBindTexture(GL_TEXTURE_2D, textureId)则将一个具体的纹理对象(由textureId标识)绑定到当前活动的纹理单元。在Cocos2d-x中,出于效率考虑,通常会维护一个状态缓存(s_currentBoundTexture),只有当纹理单元需要绑定的纹理ID发生变化时,才会实际调用OpenGL的API,避免不必要的GPU状态切换。
由于批处理通常只涉及一张纹理图集,这里的textureUnit大部分情况下是0。
BatchCommand的使用场景与效率考量
在Cocos2d-x引擎中,BatchCommand主要被ParticleBatchNode(粒子批处理节点)和SpriteBatchNode(精灵批处理节点)等组件内部使用。其典型的初始化和提交方式如下:
// 假设 _batchCommand 是一个 BatchCommand 实例
_batchCommand.init(
_globalZOrder, // 全局Z轴顺序
_shaderProgram, // 着色器程序
_blendFunc, // 混合函数
_textureAtlas, // 纹理图集
transform // 变换矩阵
);
renderer->addCommand(&_batchCommand); // 将命令添加到渲染器队列
在Cocos2d-x 3.0版本之前,将大量使用相同纹理的精灵或粒子系统分别放入SpriteBatchNode或ParticleBatchNode中,能够显著提高渲染效率。其核心原理是,对于这些共享相同纹理的元素,引擎可以只进行一次BatchCommand的execute()调用,其中包括一次着色器设置、一次纹理绑定、一次混合模式设置,然后一次性绘制所有元素,从而大幅减少CPU与GPU之间的通信开销和OpenGL状态切换的次数。然而,在3.0版本及后续版本中,由于引入了自动批处理(auto-batch)功能,引擎能够在内部智能地将符合条件的渲染命令进行批处理,因此SpriteBatchNode和ParticleBatchNode在节约效率方面的作用已不像早期版本那样突出,但它们依然是理解批处理机制的重要示例。
