深入解析回文自动机:原理、构造与进阶应用
核心概念与定义
回文自动机(Palindromic Automaton,简称 PAM),又称回文树,是一种用于高效处理字符串回文子串问题的数据结构。在探讨其原理前,需明确以下基本定义:
- 回文子串:不包含空串。
- 回文后缀:不包含原字符串本身;若不存在,则视为空串。
- 节点属性:
len[u]表示节点u所代表的回文串长度;trans[u][c]表示在节点u的状态下,两端添加字符c后的状态转移;fail[u]为失配指针,指向当前回文串的最长严格回文后缀。 - 字符集:通常用 \(\Sigma\) 表示字符集大小。
数据结构与构造原理
树形结构
回文自动机在逻辑上由两棵树构成:奇数长度树和偶数长度树。每个节点唯一对应原字符串中的一个本质不同的回文子串。
- 偶树根节点:通常编号为 0,代表长度为 0 的空串(偶数长度)。
- 奇树根节点:通常编号为 1,代表长度为 -1 的虚拟串(奇数长度),用于简化边界处理。
所有节点的 fail 指针构成了一棵以节点 1 为根的失配树(Fail Tree)。在失配树中,父节点是子节点的最长严格回文后缀,满足 len[fa] < len[son]。一个回文串的所有回文后缀,即为该节点到根节点 1 路径上所有 len > 0 的节点。
节点与边的数量
对于长度为 \(N\) 的字符串,其本质不同的回文子串数量不超过 \(N\)。这是因为每次在字符串末尾追加一个字符 \(c\) 时,新增的本质不同的回文子串必然是当前整个字符串的最长回文后缀。其他较短的回文后缀在之前的字符追加过程中必然已经出现过。
由于每个节点最多由一条转移边生成,回文自动机的节点数和转移边数均为 \(O(N)\)。失配树的边数同样为 \(O(N)\)。
增量构造法
回文自动机采用增量法构建。每次在字符串末尾追加字符 \(s[i]\) 时,核心目标是找到以 \(s[i]\) 结尾的最长回文后缀。
- 从上一个最长回文后缀对应的节点
last开始,沿着fail指针向上跳转,直到找到满足 \(s[i - len[u] - 1] == s[i]\) 的节点u。由于奇树根节点的长度为 -1,该过程必然会在根节点处终止。 - 检查
trans[u][c]是否存在。若存在,则直接更新last;若不存在,则创建新节点v,设置len[v] = len[u] + 2。 - 为新节点
v寻找fail指针:从fail[u]开始继续向上跳转,找到满足条件的节点x,则fail[v] = trans[x][c]。
核心代码实现
以下代码实现了基础的增量构造,并顺便维护了 cnt[u],表示以节点 u 结尾的回文子串总数(等于其在失配树中的深度)。
struct PalindromicAutomaton {
int trans[MAXN][26], fail[MAXN], len[MAXN], cnt[MAXN];
int sz, last;
char s[MAXN];
void init() {
len[0] = 0; fail[0] = 1; // 偶树根
len[1] = -1; fail[1] = 1; // 奇树根
sz = 2; last = 0;
}
int get_fail(int u, int i) {
while (s[i - len[u] - 1] != s[i]) u = fail[u];
return u;
}
void insert(int i) {
int c = s[i] - 'a';
int u = get_fail(last, i);
if (!trans[u][c]) {
int v = ++sz;
len[v] = len[u] + 2;
fail[v] = trans[get_fail(fail[u], i)][c];
trans[u][c] = v;
cnt[v] = cnt[fail[v]] + 1;
}
last = trans[u][c];
}
};
复杂度分析
通过势能分析可知,每次字符插入时,get_fail 函数中 fail 指针的跳转次数受限于当前节点在失配树中的深度。每跳转一次深度减 1,而每插入一个字符深度最多增加 1。由于深度始终非负,总跳转次数不超过 \(N\)。因此,构建回文自动机的时间复杂度为 \(O(N)\),空间复杂度为 \(O(N \Sigma)\)。若字符集 \(\Sigma\) 较大,可使用 std::map 或邻接链表存储转移边,将空间优化至 \(O(N)\),时间复杂度调整为 \(O(N \log \Sigma)\)。
进阶拓展:双端插入
在某些场景下,需要支持在字符串的头部和尾部同时添加字符。基于回文串的对称性,若回文串 \(t\) 的最长回文后缀为 \(t[i...|t|]\),则其最长回文前缀为 \(t[1...|t|-i+1]\),且两者完全相同。这意味着前缀和后缀的失配指针可以指向同一个节点。
实现时,只需维护两个 last 指针(分别代表前端和后端的最长回文后缀/前缀),并在两端插入时同步更新失配树结构。唯一需要注意的是,在前端插入字符时,若插入后整个字符串构成回文串,需同步更新后端的 last 指针,反之亦然。
进阶应用:最小回文划分
问题描述:将字符串 \(s\) 划分为 \(k\) 个回文子串,求 \(k\) 的最小值。\(|s| \le 5 \times 10^5\)。
朴素的动态规划状态转移方程为:\(dp[i] = \min(dp[j] + 1)\),其中 \(s[j+1...i]\) 为回文串。该算法时间复杂度为 \(O(N^2)\),无法通过大数据测试。需利用回文后缀的等差数列性质进行优化。
理论基础
回文串的后缀具有强烈的周期性,核心引理如下:
- 若 \(y\) 是 \(x\) 的最长严格回文后缀,\(z\) 是 \(y\) 的最长严格回文后缀,且 \(y = v + z, x = u + y = u + v + z\),则 \(|u| \ge |v|\)。当 \(|u| = |v|\) 时 \(u = v\);当 \(|u| > |v|\) 时 \(|u| > |z|\)。
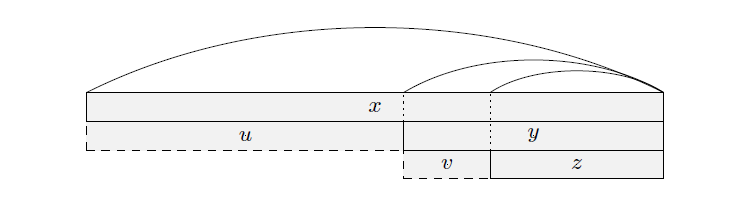
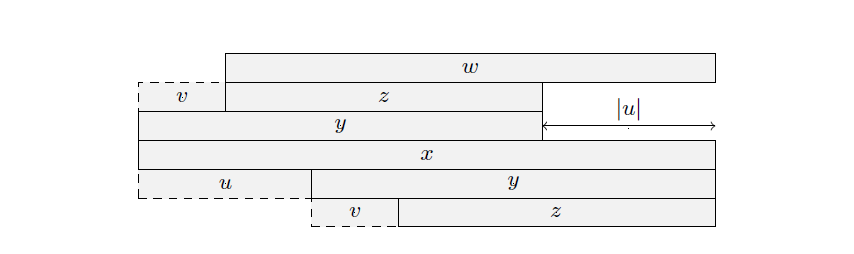
基于上述引理可推导出重要结论:一个回文串的所有回文后缀的长度,可以被划分为不超过 \(O(\log N)\) 个等差数列。
算法优化流程
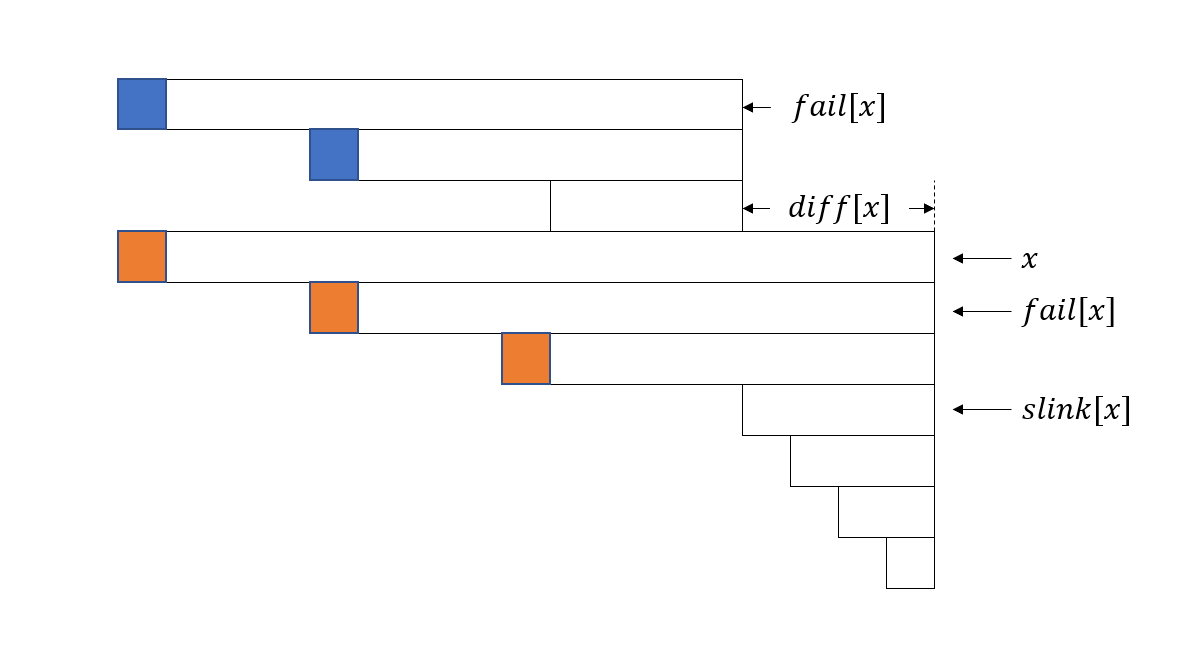
在回文自动机的节点上额外维护两个属性:
step[u]:当前节点与fail[u]的长度差,即等差数列的公差(len[u] - len[fail[u]])。series_link[u]:指向当前等差数列中长度最小的节点(即上一段等差数列的起始节点)。
在 DP 过程中,动态维护数组 dp_series[u],表示以节点 u 为最长后缀的等差数列中,所有合法划分方案的最小 DP 值。当新字符加入时,利用等差数列的性质,可以在 \(O(\log N)\) 时间内完成状态转移。
优化代码实现
int step[MAXN], series_link[MAXN];
int dp_min[MAXN], dp_series[MAXN];
void insert_opt(int i) {
int c = s[i] - 'a';
int u = get_fail(last, i);
if (!trans[u][c]) {
int v = ++sz;
len[v] = len[u] + 2;
int f_node = trans[get_fail(fail[u], i)][c];
fail[v] = f_node;
trans[u][c] = v;
step[v] = len[v] - len[fail[v]];
if (step[v] == step[fail[v]]) {
series_link[v] = series_link[fail[v]];
} else {
series_link[v] = fail[v];
}
}
last = trans[u][c];
}
void solve_partition(int n) {
dp_min[0] = 0;
for (int i = 1; i <= n; ++i) {
dp_min[i] = 1e9;
insert_opt(i);
for (int u = last; u > 1; u = series_link[u]) {
dp_series[u] = dp_min[i - len[series_link[u]] - step[u]] + 1;
if (series_link[u] != fail[u]) {
dp_series[u] = std::min(dp_series[u], dp_series[fail[u]]);
}
dp_min[i] = std::min(dp_min[i], dp_series[u]);
}
}
}
经典应用场景
不相交回文子串对数
对于求解字符串中不相交回文子串对数的问题,可采用"正难则反"的策略。分别构建正向和反向的回文自动机,统计以每个位置为右端点的回文子串数量,以及以每个位置为左端点的回文子串数量的后缀和。两者相乘并累加即可得到相交的回文子串对数,最后用总对数减去相交对数即为答案。需注意使用 map 或链表优化空间。
双倍回文串
求解最长 \(AA^R AA^R\) 形式的字符串长度。该结构必然存在一个右端点,使得其最长回文后缀即为所求。在构建 PAM 时,可额外维护一个 half_fail 指针,指向长度不超过当前节点长度一半的最长回文后缀。通过判断最长回文后缀的长度是否为 4 的倍数,且是否存在长度恰好为其一半的回文后缀,即可在 \(O(N)\) 时间内求解。
