PyTorch 深度学习模型训练全链路实现
一、数据集的初始化与加载机制
在开始构建神经网络之前,首先需要准备标准化的输入数据。本案例选用经典的 CIFAR-10 图像分类数据集,该数据集包含 10 个类别的小尺寸图片。利用 PyTorch 内置的 torchvision 库可以便捷地下载并加载数据。
import torchvision.datasets as datasets
from torch.utils.data import DataLoader
# 加载训练集,自动下载并转换为张量格式
train_dataset = datasets.CIFAR10(root="./data_root", train=True, download=True, transform=torchvision.transforms.ToTensor())
# 加载测试集
test_dataset = datasets.CIFAR10(root="./data_root", train=False, download=True, transform=torchvision.transforms.ToTensor())
# 获取数据规模信息
num_train_samples = len(train_dataset)
num_test_samples = len(test_dataset)随后,使用 DataLoader 将数据封装为迭代器,以便在训练中按批次(Batch)读取。注意需传入数据集对象而非长度数值:
batch_size = 64
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False)二、卷积神经网络结构设计
定义网络结构时,通常继承自 nn.Module。以下是一个针对 CIFAR-10 优化的三层卷积网络示例,最后接全连接层输出类别概率。
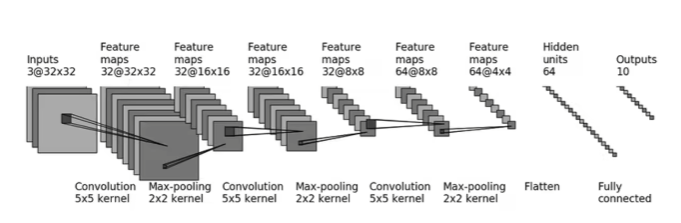
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
# 卷积块:卷积层 + 池化层
self.feature_extractor = nn.Sequential(
# 输入通道 3,输出 32,核大小 5x5,填充 2 保持尺寸
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Flatten(),
# 全连接层
nn.Linear(in_features=64 * 4 * 4, out_features=64),
nn.ReLU(inplace=True),
nn.Linear(in_features=64, out_features=10)
)
def forward(self, x):
features = self.feature_extractor(x)
return features为了验证维度是否正确,可以在实例化后进行一次前向传播测试:
if __name__ == "__main__":
model = SimpleCNN()
dummy_input = torch.randn(64, 3, 32, 32) # 模拟一个 batch 的输入
output = model(dummy_input)
assert output.shape == (64, 10), "Output dimensions mismatch"三、训练超参数与优化配置
确定好网络架构后,需要定义损失函数和优化器。对于多分类问题,交叉熵损失(Cross Entropy)是标准选择;优化器这里选用随机梯度下降(SGD)。
# 实例化模型
network = SimpleCNN()
# 定义损失函数
criterion = nn.CrossEntropyLoss()
# 设置学习率与优化器
lr = 1e-2
optimizer = torch.optim.SGD(network.parameters(), lr=lr)
# 引入 TensorBoard 用于实验监控
writer = SummaryWriter(log_dir="runs/log_output")
epochs = 10
total_steps = 0
eval_step_counter = 0四、训练循环与模式切换
训练的精髓在于正确地控制模型状态和梯度更新。需要注意两个关键点:
- 模型状态:训练时调用
.train(),测试时调用.eval()。这直接影响 Dropout 和 BatchNorm 层的统计行为。 - 梯度计算:测试或推理阶段不需要计算梯度以节省显存,应使用
with torch.no_grad():上下文管理器。
完整的 Epoch 循环逻辑如下:
for epoch in range(epochs):
print(f"--- 开始第 {epoch+1} 轮训练 ---")
# 1. 开启训练模式
network.train()
for imgs, labels in train_loader:
# 前向传播
preds = network(imgs)
current_loss = criterion(preds, labels)
# 反向传播流程
optimizer.zero_grad() # 清零旧梯度
current_loss.backward() # 计算新梯度
optimizer.step() # 更新权重
total_steps += 1
# 周期性打印训练损耗
if total_steps % 100 == 0:
print(f"步骤 [{total_steps}] Loss: {current_loss.item():.4f}")
writer.add_scalar("Train/Loss", current_loss.item(), total_steps)
# 2. 切换到评估模式并保存当前轮次模型
network.eval()
running_loss = 0.0
correct_predictions = 0
# 3. 无梯度评估
with torch.no_grad():
for test_imgs, test_labels in test_loader:
test_outputs = network(test_imgs)
loss_val = criterion(test_outputs, test_labels)
running_loss += loss_val.item()
# 计算准确率:比较预测最大值索引与真实标签
_, predicted = torch.max(test_outputs, dim=1)
correct_predictions += (predicted == test_labels).sum().item()
avg_test_loss = running_loss / len(test_loader)
accuracy = correct_predictions / num_test_samples
print(f"本轮测试集 Loss: {avg_test_loss:.4f}, 准确率:{accuracy:.4f}")
# 记录日志
writer.add_scalar("Test/Loss", avg_test_loss, eval_step_counter)
writer.add_scalar("Test/Accuracy", accuracy, eval_step_counter)
eval_step_counter += 1
# 保存模型权重
checkpoint_path = f"./models/checkpoint_epoch_{epoch}.pth"
torch.save(network.state_dict(), checkpoint_path)
print("模型权重已保存.")五、关键技术点解析
1. 关于 requires_grad 与内存优化
默认情况下,PyTorch 会记录运算历史以便反向传播求导。当设置 requires_grad=True 时,相关操作会占用额外显存存储计算图。若仅需前向推理(如测试阶段),强制使用 torch.no_grad() 可显著降低资源消耗。
2. argmax 与准确率统计output.argmax(dim=1) 用于获取每个样本中概率最大的类别索引。将其与真实标签 targets 进行布尔比较并求和,即可得到当前 Batch 中的正确样本数。
3. 状态保存最佳实践
建议使用 model.state_dict() 保存可训练参数的键值对字典,而非直接序列化整个 Module 对象。这种方式更灵活,便于后续加载到不同版本的网络结构中。
六、整合后的参考实现
import torch
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from torch import nn
# 定义网络类
class ClassificationNet(nn.Module):
def __init__(self):
super().__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, padding=2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
return self.features(x)
def main():
# 数据准备
transform = transforms.ToTensor()
train_set = torchvision.datasets.CIFAR10("./data", train=True, transform=transform, download=True)
test_set = torchvision.datasets.CIFAR10("./data", train=False, transform=transform, download=True)
train_loader = DataLoader(train_set, batch_size=64, shuffle=True)
test_loader = DataLoader(test_set, batch_size=64, shuffle=False)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = ClassificationNet().to(device)
# 训练配置
loss_func = nn.CrossEntropyLoss()
optim = torch.optim.SGD(model.parameters(), lr=0.01)
writer = SummaryWriter("logs/cifar_run")
epochs = 10
global_step = 0
for i in range(epochs):
print(f"[Epoch {i+1}/{epochs}] 开始训练")
model.train() # 确保 BN 和 Dropout 处于激活状态
for imgs, targets in train_loader:
imgs, targets = imgs.to(device), targets.to(device)
outputs = model(imgs)
loss = loss_func(outputs, targets)
optim.zero_grad()
loss.backward()
optim.step()
global_step += 1
if global_step % 100 == 0:
writer.add_scalar("loss/train", loss.item(), global_step)
# 评估阶段
model.eval() # 关闭 BN 和 Dropout 的随机性
test_acc_total = 0
test_loss_accum = 0
with torch.no_grad():
for t_imgs, t_targets in test_loader:
t_imgs, t_targets = t_imgs.to(device), t_targets.to(device)
preds = model(t_imgs)
test_loss_accum += loss_func(preds, t_targets).item()
pred_class = preds.argmax(dim=1)
test_acc_total += (pred_class == t_targets).sum().item()
avg_acc = test_acc_total / len(test_set)
print(f"验证集准确率:{avg_acc:.4f}")
writer.add_scalar("metrics/accuracy", avg_acc, i)
writer.add_scalar("loss/test", test_loss_accum/len(test_loader), i)
# 保存检查点
torch.save(model.state_dict(), f"./saved_models/ep_{i}.pt")
writer.close()
if __name__ == "__main__":
main()