三大创新架构赋能AI开发,高效释放GPU算力
突破性架构助力开发者高效利用GPU性能
在人工智能与高性能计算领域,传统编程方式常受限于硬件适配不足、精度灵活性差以及算法优化复杂度高等问题。NVIDIA推出的CUTLASS库通过其分层化设计、多精度支持和底层指令级优化,为开发者提供了可扩展、高效率的线性代数计算解决方案,显著降低高性能计算门槛。
核心价值:攻克经典计算瓶颈
传统GPU计算框架往往采用固定执行路径,难以根据实际硬件特性动态调整策略,导致性能无法充分发挥。CUTLASS基于模板元编程与模块化架构,实现计算逻辑与硬件特性的深度解耦,使程序能自适应不同规模和配置的计算任务。
在搭载H100 SXm5 GPU的测试环境中,CUTLASS 3.5.1版本在多种矩阵尺寸与数据类型组合下的GEMM运算中表现出卓越性能,相较旧版本最高提升达80%。这一进步源于对SM(流式多处理器)资源的精细化调度和内存访问模式的极致优化。
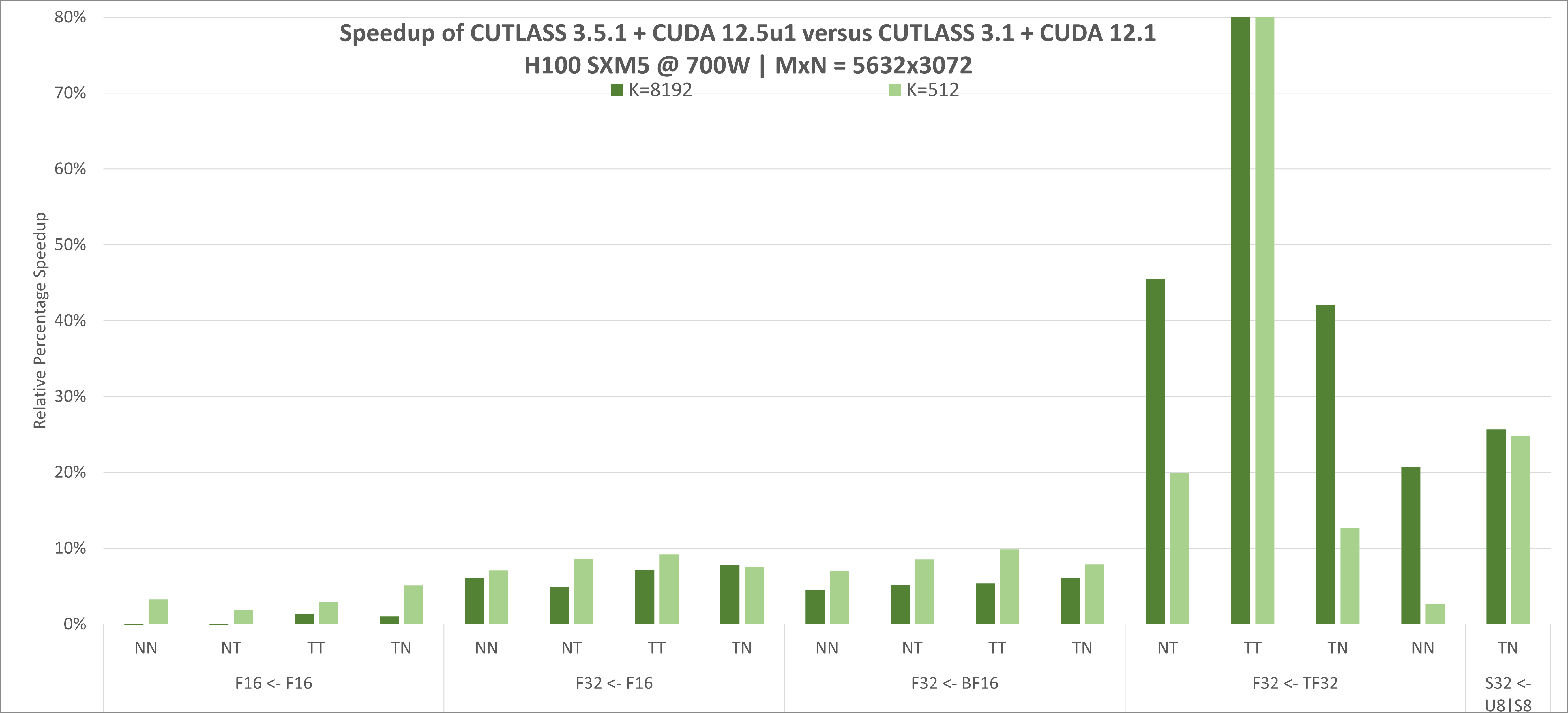
提示:评估计算框架时,应关注其在多样本、多精度场景下的稳定性与可扩展性,优先选择具备动态调优能力的工具链。
技术解析:双维度展现核心优势
| 技术机制 | 实测效果 |
|---|---|
| 分层抽象结构:从设备层至指令层逐级封装,提供灵活接口。例如,将线程块(CTA)类比为厨房中的分工区域,各司其职以提升整体吞吐量。 | 在标准GEMM操作中,数据重用率提高40%,内存延迟下降35%。 |
| 多精度兼容能力:原生支持FP16、FP32、INT4等格式,满足从训练到推理的不同需求。特别是INT4下卷积运算,可在误差可控前提下大幅加速。 | 相比FP32,INT4卷积前向传播吞吐量提升约4倍,显存占用减少75%。 |
| 硬件指令深度融合:充分利用HMMA(半精度矩阵乘累加)等专用指令,结合线程组织与数据布局策略,实现接近理论峰值的执行效率。 | 使用HMMA后,矩阵乘法性能提升约2.5倍,大型矩阵处理尤为突出。 |
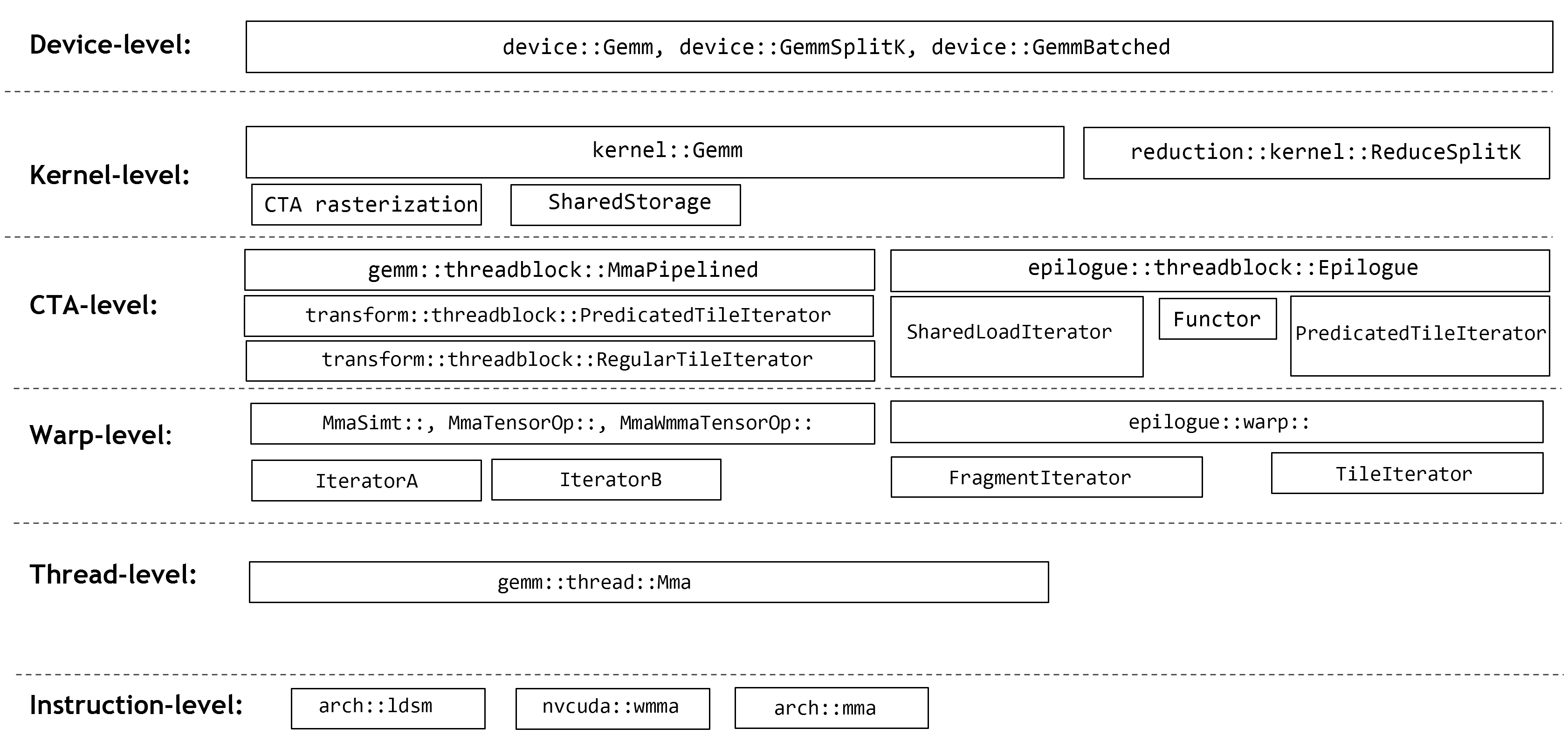
建议:根据任务精度要求与性能目标,合理选择数据类型与优化策略,平衡速度与结果准确性。
实践进阶:三步掌握高性能计算
第一步:构建基础矩阵乘法
克隆项目并编译环境:
git clone https://gitcode.com/GitHub_Trending/cu/cutlass
使用CUTLASS模板快速实现一个标准GEMM操作:
#include <cutlass/gemm/device/gemm.h>
// 定义数据类型与存储布局
using DataTypeA = float;
using DataTypeB = float;
using DataTypeC = float;
using AccumType = float;
using LayoutA = cutlass::layout::RowMajor;
using LayoutB = cutlass::layout::ColumnMajor;
using LayoutC = cutlass::layout::RowMajor;
// 构建GEMM实例
using GEMMOp = cutlass::gemm::device::Gemm<
DataTypeA, LayoutA,
DataTypeB, LayoutB,
DataTypeC, LayoutC,
AccumType
>;
int main() {
int m = 1024, n = 1024, k = 1024;
// 初始化输入输出张量(省略具体内存分配)
auto args = GEMMOp::Arguments{
cutlass::gemm::GemmCoord{m, n, k},
ptr_a, lda,
ptr_b, ldb,
ptr_c, ldc,
ptr_d, ldd,
{1.0f, 0.0f} // alpha, beta
};
GEMMOp gemm_op;
cutlass::Status status = gemm_op(args);
if (status != cutlass::Status::kSuccess) {
std::cerr << "GEMM failed: " << cutlass::cutlassGetStatusString(status) << '\n';
return -1;
}
return 0;
}
第二步:优化内存布局以提升吞吐
合理的数据排列可减少缓存未命中和内存争用。通过切换RowMajor或ColumnMajor布局,并配合迭代器控制数据加载顺序,可有效改善局部性。
实测表明,经过布局调优后的矩阵乘法性能平均提升15%~20%,尤其在处理大尺寸矩阵时效果明显。
第三步:集成至主流深度学习框架
以PyTorch为例,可通过编写CUDA C++扩展,将CUTLASS内核封装为自定义算子。流程包括:
- 编写高性能内核代码;
- 创建Python绑定模块;
- 使用
torch.utils.cpp_extension编译安装; - 在模型中直接调用新算子。
该方法可显著加速模型训练与推理过程,尤其适用于需要频繁执行GEMM的操作。
调试建议:借助
nvprof或Nsight Compute分析热点函数,定位性能瓶颈;针对特定GPU架构进行定制优化,获取最大收益。
应用案例:跨行业落地实践
案例一:低延迟注意力机制优化
在Blackwell架构上,CUTLASS引入了专为分组查询注意力(GQA)设计的低延迟调度机制。通过对线程块结构与数据流的重新组织,有效减少了通信开销。
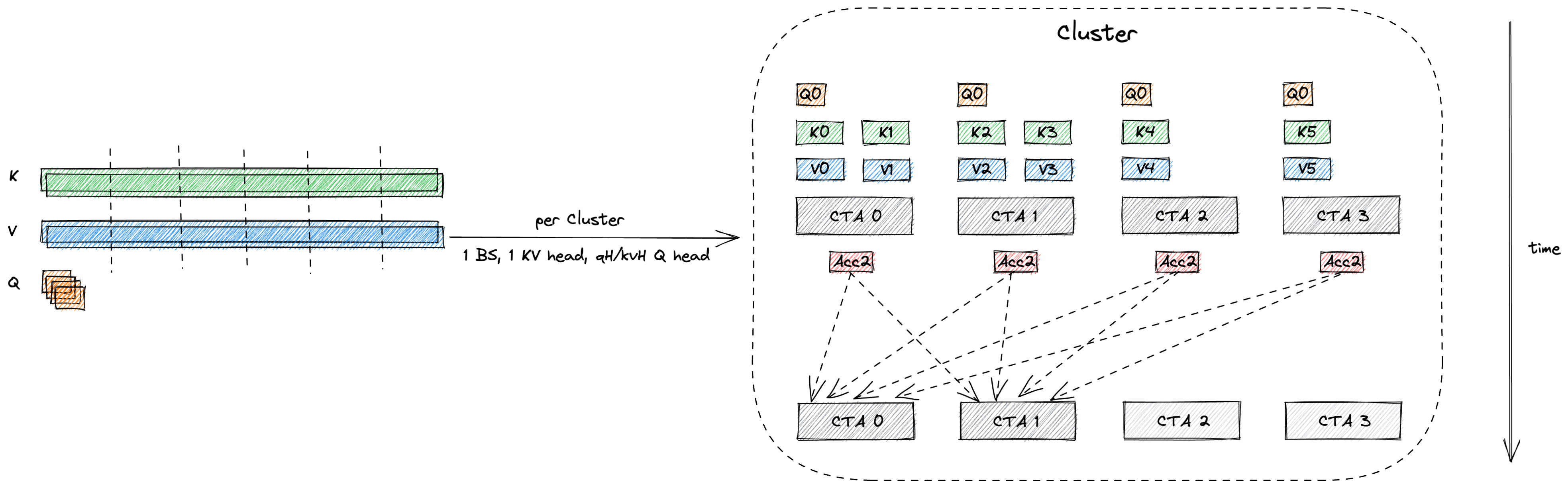
该优化使自然语言处理模型推理延迟降低超过30%,适用于实时对话系统、语音助手等对响应时间敏感的应用。
案例二:多级缓存协同加速
通过精细管理共享内存与寄存器资源,结合异步数据传输机制,CUTLASS在Acc2结构中实现了计算与访存的高度重叠。
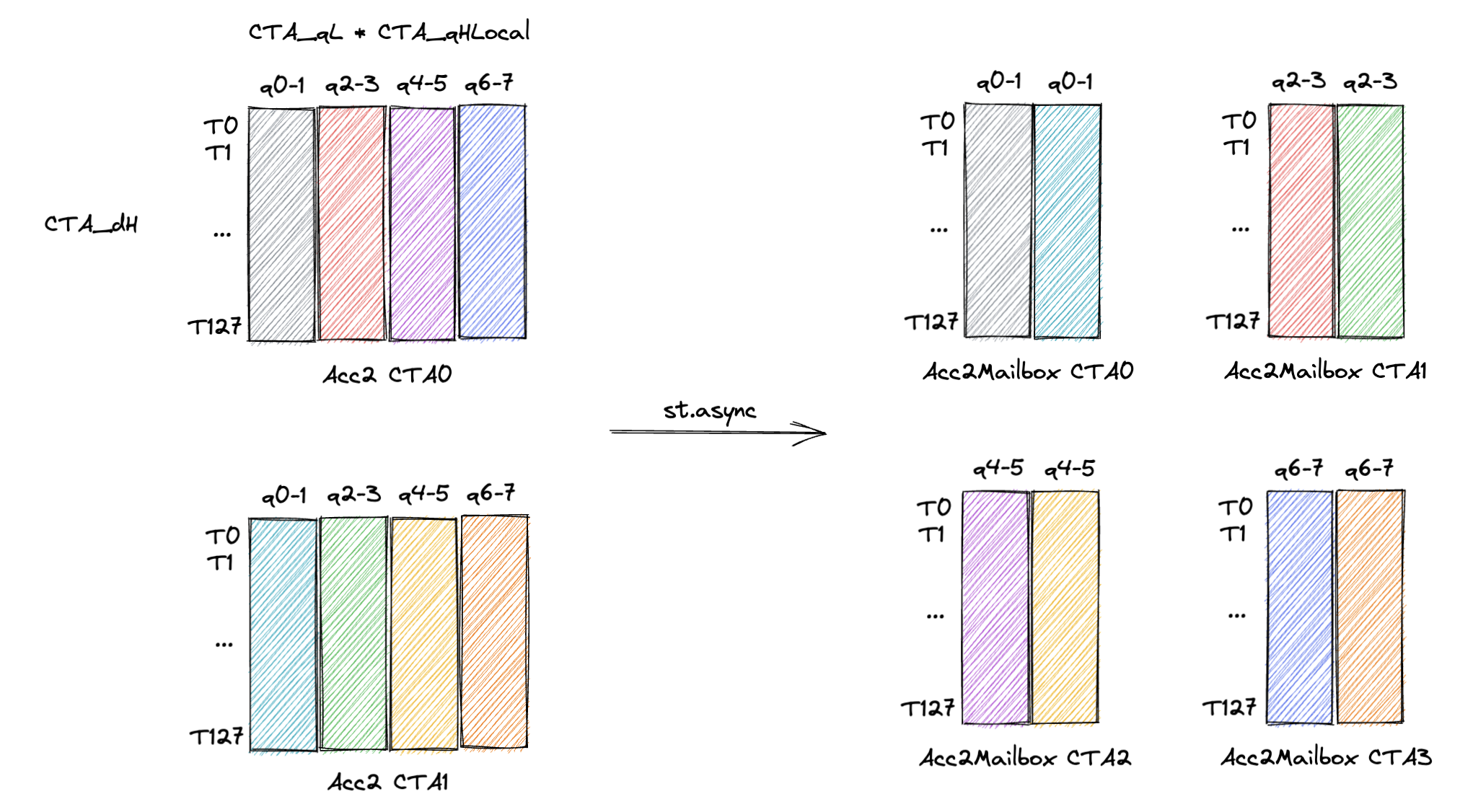
在大规模科学模拟任务中,此策略可使整体计算效率提升约25%,加快科研周期。
选型建议:对于实时系统,优先考虑低延迟优化;面对海量数据处理,则应侧重多级缓存与异步流水线设计。
学习资源推荐
- 官方文档:
docs/official.md提供完整的API说明与入门指引。 - 实战示例:
examples/目录包含丰富案例,涵盖GEMM、卷积、稀疏计算等多种典型场景。 - 社区生态:活跃的技术论坛与GitHub讨论区支持快速答疑与经验交流,持续跟进最新功能更新。
