PyTorch基础教程
一、环境搭建与核心概念
1.1 环境配置流程
通过Anaconda创建虚拟环境:
conda create -n torch_env python=3.6
确认安装选项后输入y继续。访问官方文档获取适配CPU的安装指令,进入目标环境执行:
conda install pytorch torchvision torchaudio cpuonly -c pytorch
验证安装状态可通过以下方式:
 (或执行
(或执行print(torch.cuda.is_available())返回False表示CPU版本)
1.2 开发工具选择
配置PyCharm时需确保解释器指向正确环境。对于Jupyter Notebook,安装依赖包后可能需要调整版本兼容性:
conda install nb_conda
conda install tornado=4.5
启动后选择对应内核创建文件,输入import torch验证环境有效性。
1.3 核心调试方法
模块管理类比为工具集合:
 (1)dir()函数用于查看模块成员列表
(2)help()函数提供具体方法说明
(1)dir()函数用于查看模块成员列表
(2)help()函数提供具体方法说明
示例```
dir(torch) ['AVG', 'AggregationType', ... 'cuda', ...] dir(torch.cuda) ['Any', 'BFloat16Storage', ... 'is_available', ...] help(torch.cuda.is_available) is_available() -> bool Returns a bool indicating if CUDA is currently available.
1.4 执行模式对比
--------------
| | 脚本执行 | 控制台交互 | Notebook模式 |
|---|---|---|---|
| 执行粒度 | 整体运行 | 单行执行 | 单元格执行 |
| 优势 | 便于版本管理 | 实时变量检查 | 交互式开发 |
| 劣势 | 调试不便 | 代码组织困难 | 环境依赖 |
二、数据处理实践
===========
PyTorch数据处理核心组件:
| 数据集类 | 数据加载器 |
|---|---|
| 管理样本与标签 | 提供迭代接口 |
数据目录结构示例
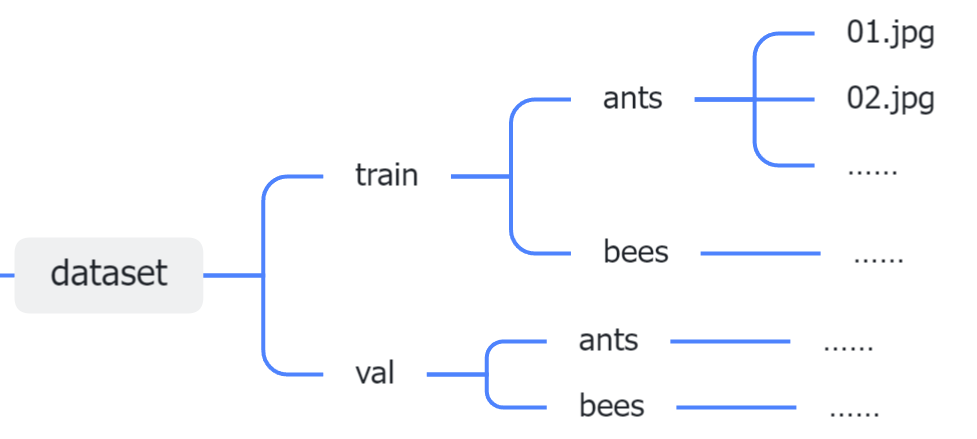
操作步骤
① 将数据文件夹移至项目根目录
② 图像读取示例:
方式一
from PIL import Image img = Image.open("path\to\image.jpg")
方式二
import cv2 img_data = cv2.imread("path\to\image.jpg")
③ 自定义数据集实现:
代码示例```
from torch.utils.data import Dataset
from PIL import Image
import os
class CustomDataset(Dataset):
def __init__(self, root, label):
self.root = root
self.label = label
self.file_list = os.listdir(os.path.join(root, label))
def __getitem__(self, index):
file_name = self.file_list[index]
file_path = os.path.join(self.root, self.label, file_name)
image = Image.open(file_path)
return image, self.label
def __len__(self):
return len(self.file_list)
# 使用示例
train_data = CustomDataset("data/train", "cats") + CustomDataset("data/train", "dogs")
