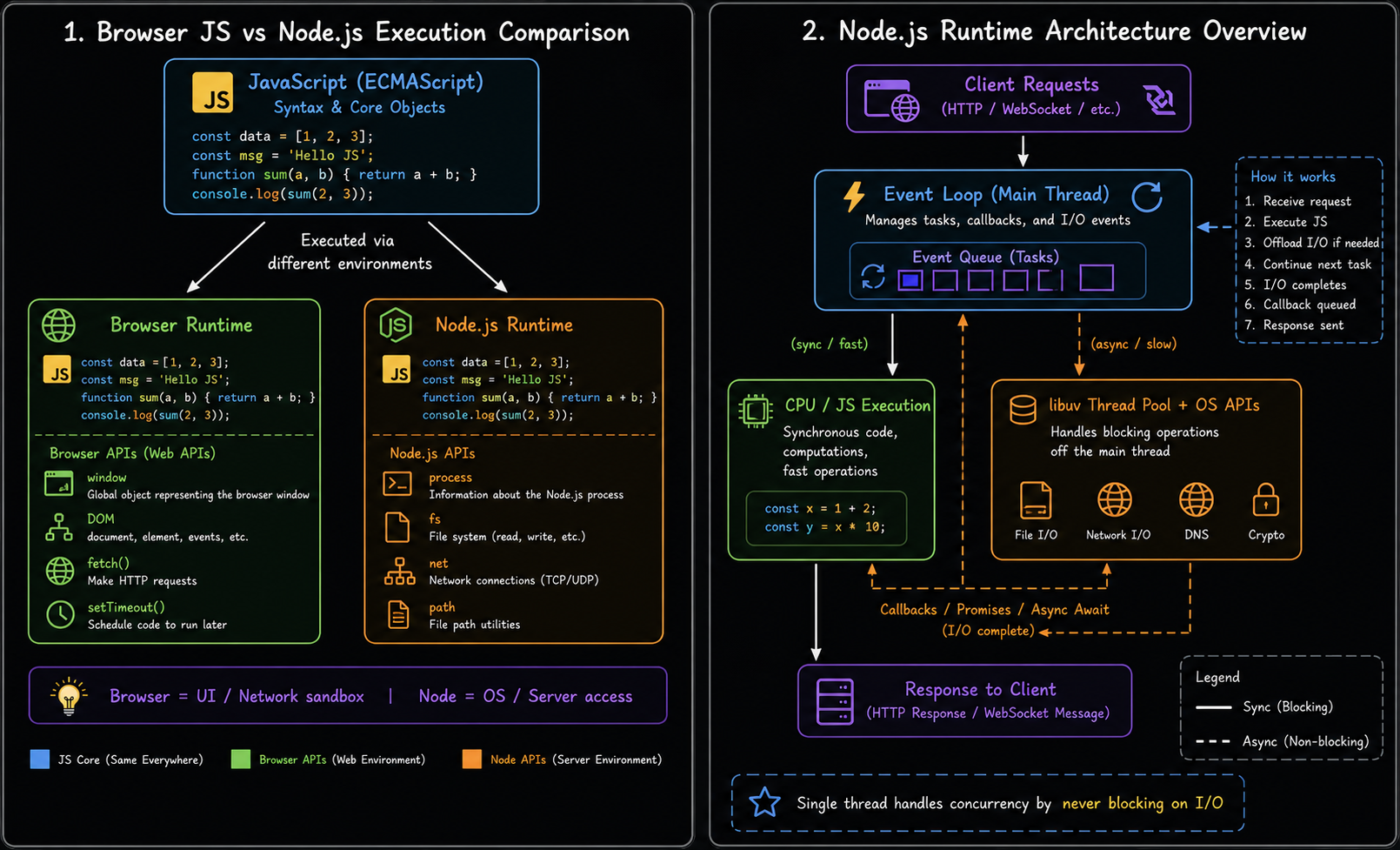
基于泛型的循环队列实现与应用
任务目标
设计并实现一个支持多种数据类型的队列结构,使用泛型机制保证类型安全,并完成基本的入队和出队操作验证。
知识点掌握
- 理解Java泛型的基本原理及其在类定义中的作用
- 掌握泛型类的声明方式及其实例化过程
- 熟悉数组实现的循环队列逻辑
实现要求
1. 项目结构创建
新建一个标准Java应用程序,根包命名为GenericQueue。所有源文件需按以下目录结构组织:
GenericQueue/
└── src/
├── GenericQueue/
│ └── Main.java
└── GenericQueue/util/
└── ArrayQueue.java
2. 泛型队列类设计(ArrayQueue)
在GenericQueue.util包中定义名为ArrayQueue的泛型类,具体要求如下:
- 使用内部数组存储元素,支持任意引用类型数据
- 包含两个构造函数:
- 无参构造:初始化容量为16的队列
- 带参构造:接收整型参数作为队列大小,若值小于等于0则抛出
IllegalArgumentException
- 维护队头索引(front)、队尾索引(rear)以及当前元素数量(size)以管理队列状态
- 提供以下公共方法:
方法名 参数 返回类型 功能说明 isEmpty - boolean 判断队列是否为空 isFull - boolean 判断队列是否已满 add T item void 将指定元素添加至队尾,队满时抛出异常 remove - T 移除并返回队首元素,队空时抛出异常
代码实现
package GenericQueue.util;
public class ArrayQueue<T> {
private T[] data;
private int frontIndex;
private int rearIndex;
private int count;
private int totalCapacity;
public ArrayQueue() {
this(16);
}
public ArrayQueue(int capacity) {
if (capacity <= 0) {
throw new IllegalArgumentException("队列容量必须大于零:" + capacity);
}
this.totalCapacity = capacity;
this.count = 0;
this.frontIndex = 0;
this.rearIndex = 0;
@SuppressWarnings("unchecked")
T[] array = (T[]) new Object[capacity];
this.data = array;
}
public boolean isEmpty() {
return count == 0;
}
public boolean isFull() {
return count == totalCapacity;
}
public void add(T element) {
if (isFull()) {
throw new IllegalStateException("无法添加元素,队列已满");
}
data[rearIndex] = element;
rearIndex = (rearIndex + 1) % totalCapacity;
count++;
}
public T remove() {
if (isEmpty()) {
throw new IllegalStateException("无法删除元素,队列为空");
}
T value = data[frontIndex];
data[frontIndex] = null; // 帮助GC回收
frontIndex = (frontIndex + 1) % totalCapacity;
count--;
return value;
}
}
主类测试逻辑(Main)
在GenericQueue包下创建Main类,用于验证队列功能:
package GenericQueue;
import GenericQueue.util.ArrayQueue;
public class Main {
public static void main(String[] args) {
ArrayQueue<Integer> queue = new ArrayQueue<>(10);
System.out.println("测试进队: ");
for (int i = 1; i < 20; i++) {
if (!queue.isFull()) {
queue.add(i);
System.out.printf("[%d] added. \n", i);
} else {
System.out.printf("队列已满, [%d] 未添加。\n", i);
}
}
System.out.println("测试出队: ");
while (!queue.isEmpty()) {
System.out.printf("[%d] removed.\n", queue.remove());
}
}
}
构建与提交说明
将整个项目的src目录打包为ZIP格式文件进行提交,确保包内包含正确的包路径和Java源码文件。
运行预期输出
测试进队:
[1] added.
[2] added.
...
[10] added.
队列已满, [11] 未添加。
...
队列已满, [19] 未添加。
测试出队:
[1] removed.
[2] removed.
...
[10] removed.