ECS Fargate 与 App Runner:Laravel 容器化部署实战
Lambda 的局限性
之前我写过一篇关于使用 Bref 和 Terraform 将 Laravel 部署到 AWS Lambda 的文章。这种方案覆盖了 Laravel 应用的大部分需求,包括 API 端点、网页、后台任务、定时命令,Lambda 都能很好地处理。
但有一个问题很难通过架构设计解决。当时我在开发一个视频处理功能:用户上传文件到 S3,一个队列任务获取文件后运行 FFmpeg 进行转码,再把结果推回去。理论上很简单,但某些任务根据文件大小需要 25 到 40 分钟,而 Lambda 的执行时间上限是 15 分钟。我尝试把工作拆分成更小的块,在多次调用之间传递状态。这种方式勉强可行,但序列化开销让整个系统变得脆弱,代码也写得很难看。这让我开始认真考虑容器方案。
Lambda 确实存在 15 分钟的执行时间硬上限,这是无法绕过的限制。如果你要处理大文件、运行长时间的机器学习任务,或者队列处理程序需要消耗大量时间,这种方式就行不通。另外,WebSocket 连接也很别扭,因为处理连接的 Lambda 每 15 分钟就会重启。处理图片批量任务时我还遇到过临时存储空间不足的问题,当时没意识到 /tmp 目录会这么快填满。
如果一直关注这个系列,你会发现前面介绍过 EC2 方案和 Fastify 的无服务器 SaaS 架构。容器方案处于两者之间。ECS Fargate 让你控制容器但无需管理 EC2 实例,而 App Runner 更是把大部分基础设施细节都隐藏起来了。下面深入了解这两种方案。
架构概览
本文构建的架构如下:
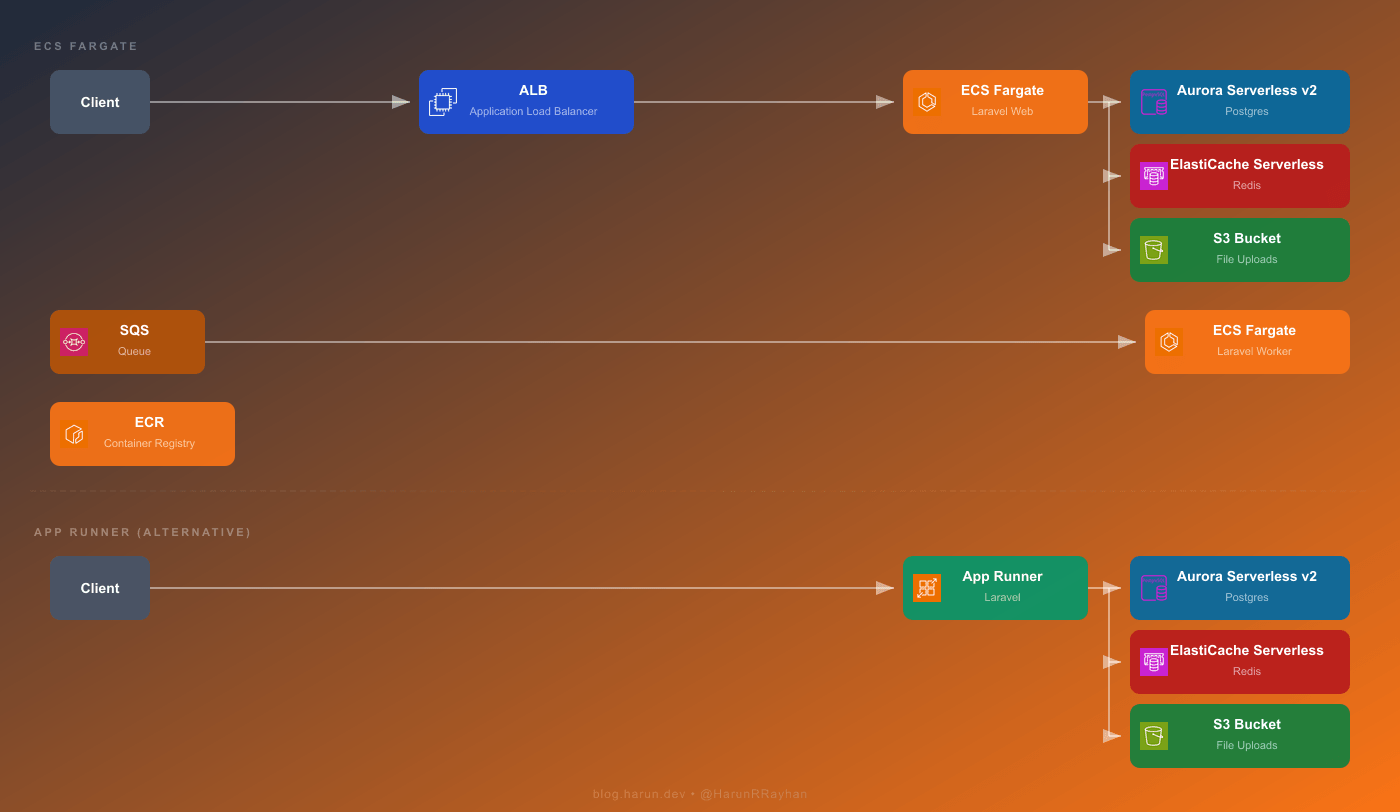
图中展示了两条路径,具体选择取决于应用的真实需求。
Fargate 路径是功能完整的方案。请求首先到达应用负载均衡器,然后转发到运行 Laravel 应用的 ECS Fargate 任务(Docker 容器)。这些任务连接 Aurora Serverless v2(Postgres)、ElastiCache Serverless(Redis)和 S3(文件存储)。后台处理通过 SQS 实现,SQS 将消息发送给单独的一组 Fargate 任务,这些任务运行 php artisan queue:work。Web 任务和 Worker 任务都从 ECR 获取容器镜像。
App Runner 路径则简洁得多。客户端请求直接发往 App Runner,它自动处理负载均衡、TLS 终止和自动扩展。虽然底层仍在运行容器,但你完全不需要接触网络层。App Runner 同样连接 Aurora、ElastiCache 和 S3。
两条路径使用完全相同的 Docker 镜像。构建一次,推送到 ECR,两种服务都能运行。这种可移植性确实是采用容器的一大优势。
关键问题是你想掌控多少基础设施。Fargate 提供网络控制、自定义自动扩展和 SQS 驱动的 Worker,但要写的 Terraform 代码量很大。App Runner 几乎移除了所有这些复杂度。我用它部署过内部工具,当时只想在 10 分钟内让服务上线,完全不想操心 ALB 或目标组。对于有队列任务且网络要求严格的生产环境,Fargate 仍然是更好的选择。
Docker 化 Laravel
在 Fargate 或 App Runner 能做任何事情之前,我们需要一个可用于生产的 Docker 镜像。我采用多阶段构建,这样最终镜像体积小,不包含开发依赖或构建工具。
# 阶段 1:Composer 依赖安装 FROM composer:2 AS vendor WORKDIR /app COPY composer.json composer.lock ./ RUN composer install --no-dev --optimize-autoloader --classmap-authoritative --no-scripts # 阶段 2:前端资源构建 FROM node:20-alpine AS assets WORKDIR /app COPY package.json package-lock.json ./ RUN npm ci COPY . . RUN npm run build # 阶段 3:生产镜像 FROM php:8.3-fpm-alpine AS production RUN apk add --no-cache nginx supervisor curl \ && docker-php-ext-install pdo pdo_pgsql opcache RUN apk add --no-cache autoconf g++ make \ && pecl install redis \ && docker-php-ext-enable redis \ && apk del autoconf g++ make WORKDIR /var/www/html COPY --from=vendor /app/vendor ./vendor COPY --from=assets /app/public/build ./public/build COPY . . COPY docker/nginx.conf /etc/nginx/nginx.conf COPY docker/supervisord.conf /etc/supervisor/conf.d/supervisord.conf COPY docker/php.ini /usr/local/etc/php/conf.d/custom.ini RUN php artisan config:cache \ && php artisan route:cache \ && php artisan view:cache \ && php artisan event:cache EXPOSE 80 CMD ["/usr/bin/supervisord", "-c", "/etc/supervisor/conf.d/supervisord.conf"]
第一个阶段在独立层中安装 Composer 依赖。第二个阶段通过 Vite 或 Mix 处理前端资源编译。第三个阶段是基于 Alpine 的实际运行时环境。Supervisor 在容器内同时运行 Nginx 和 PHP-FPM,这是 Laravel 单容器部署的标准方式,效果很好。
还需要一个 .dockerignore 文件,防止无关文件污染构建上下文:
.git .env node_modules storage/logs tests docker-compose.yml
接下来将镜像推送到 ECR。先创建仓库(如不存在),进行身份验证,然后推送:
# 身份验证 aws ecr get-login-password --region us-east-1 | \ docker login --username AWS --password-stdin \ 123456789012.dkr.ecr.us-east-1.amazonaws.com # 构建并标记 docker build -t demo-laravel-app:latest . docker tag demo-laravel-app:latest \ 123456789012.dkr.ecr.us-east-1.amazonaws.com/demo-laravel-app:latest # 推送 docker push 123456789012.dkr.ecr.us-east-1.amazonaws.com/demo-laravel-app:latest
需要注意的是,首次构建可能需要 5 到 8 分钟,因为需要下载基础镜像并从头编译 PHP 扩展。之后由于 Docker 的层缓存机制,只要不更改 Composer 或 npm 依赖,后续构建在一分钟内就能完成。另外非常重要的一点:不要把 .env 文件打包进 Docker 镜像。环境变量应该放在 ECS 任务定义或 App Runner 运行时配置中。我在 staging 环境上吃过这个亏,花了很长时间才发现生产环境的密钥为什么会出现在 staging 日志里——.env 文件就躺在镜像里。
ECS Fargate 与 Terraform 配置
这部分代码量较大。需要创建 ECR 仓库、ECS 集群、任务定义、ALB,以及把它们串联起来的服务。下面逐个讲解。
ECR 仓库
resource "aws_ecr_repository" "demo_laravel_ecr" {
name = "demo-laravel-app"
force_delete = true
image_scanning_configuration {
scan_on_push = true
}
tags = { Name = "demo-laravel-ecr" }
}设置 force_delete = true 允许 Terraform 在仓库仍有镜像时也能删除。这在迭代开发时很方便,但在生产环境最好去掉这个标志。
CloudWatch 日志组和 ECS 集群
resource "aws_cloudwatch_log_group" "demo_laravel_logs" {
name = "/ecs/demo-laravel-web"
retention_in_days = 7
tags = { Name = "demo-laravel-logs" }
}
resource "aws_ecs_cluster" "demo_laravel_cluster" {
name = "demo-laravel-cluster"
setting {
name = "containerInsights"
value = "enabled"
}
tags = { Name = "demo-laravel-cluster" }
}日志保留 7 天对开发环境来说足够,成本也低。生产环境建议改为 30 或 90 天。Container Insights 功能让你无需额外配置就能获得 CPU 和内存指标。
任务定义
这是复杂度最高的部分:
resource "aws_ecs_task_definition" "demo_laravel_web_task" {
family = "demo-laravel-web"
network_mode = "awsvpc"
requires_compatibilities = ["FARGATE"]
cpu = "512"
memory = "1024"
execution_role_arn = aws_iam_role.demo_ecs_execution_role.arn
task_role_arn = aws_iam_role.demo_ecs_task_role.arn
runtime_platform {
operating_system_family = "LINUX"
cpu_architecture = "ARM64"
}
container_definitions = jsonencode([
{
name = "demo-laravel-web"
image = "${aws_ecr_repository.demo_laravel_ecr.repository_url}:latest"
essential = true
portMappings = [
{
containerPort = 80
protocol = "tcp"
}
]
healthCheck = {
command = ["CMD-SHELL", "curl -f http://localhost/health || exit 1"]
interval = 30
timeout = 5
retries = 3
startPeriod = 60
}
environment = [
{ name = "APP_ENV", value = "production" },
{ name = "APP_KEY", value = var.app_key },
{ name = "DB_CONNECTION", value = "pgsql" },
{ name = "DB_HOST", value = aws_rds_cluster.demo_laravel_db.endpoint },
{ name = "DB_PORT", value = "5432" },
{ name = "DB_DATABASE", value = "demo_laravel" },
{ name = "DB_USERNAME", value = "demo_admin" },
{ name = "DB_PASSWORD", value = var.db_password },
{ name = "REDIS_HOST", value = aws_elasticache_serverless_cache.demo_laravel_cache.endpoint[0].address },
{ name = "REDIS_PORT", value = "6379" },
{ name = "CACHE_STORE", value = "redis" },
{ name = "SESSION_DRIVER", value = "redis" },
{ name = "LOG_CHANNEL", value = "stderr" },
{ name = "QUEUE_CONNECTION", value = "sqs" },
{ name = "SQS_QUEUE", value = aws_sqs_queue.demo_laravel_queue.url },
{ name = "FILESYSTEM_DISK", value = "s3" },
{ name = "AWS_BUCKET", value = aws_s3_bucket.demo_laravel_uploads.id },
]
logConfiguration = {
logDriver = "awslogs"
options = {
"awslogs-group" = aws_cloudwatch_log_group.demo_laravel_logs.name
"awslogs-region" = var.aws_region
"awslogs-stream-prefix" = "web"
}
}
}
])
tags = { Name = "demo-laravel-web-task" }
}健康检查中的 startPeriod = 60 比想象中更重要。初次启动时,Aurora Serverless 可能刚从冷状态唤醒,首次数据库连接有时需要 10 到 20 秒。如果没有这个启动缓冲期,ECS 会在 Laravel 完成数据库连接之前就判定任务不健康。我见过任务在 "RUNNING" 和 "STOPPED" 之间来回切换了整整 20 分钟,最后才发现是这个原因,非常令人沮丧。选择 ARM64 架构的原因与 Lambda 类似——在 Fargate 上比 x86 便宜约 20%。
应用负载均衡器
resource "aws_lb" "demo_laravel_alb" {
name = "demo-laravel-alb"
internal = false
load_balancer_type = "application"
security_groups = [aws_security_group.demo_alb_sg.id]
subnets = [
aws_subnet.demo_public_a.id,
aws_subnet.demo_public_b.id,
]
tags = { Name = "demo-laravel-alb" }
}
resource "aws_lb_target_group" "demo_laravel_tg" {
name = "demo-laravel-tg"
port = 80
protocol = "HTTP"
vpc_id = aws_vpc.demo_laravel_vpc.id
target_type = "ip"
health_check {
path = "/health"
protocol = "HTTP"
healthy_threshold = 2
unhealthy_threshold = 3
timeout = 10
interval = 30
matcher = "200"
}
tags = { Name = "demo-laravel-tg" }
}
resource "aws_lb_listener" "demo_laravel_listener" {
load_balancer_arn = aws_lb.demo_laravel_alb.arn
port = 80
protocol = "HTTP"
default_action {
type = "forward"
target_group_arn = aws_lb_target_group.demo_laravel_tg.arn
}
}目标类型设为 ip,因为使用 awsvpc 网络模式的 Fargate 任务每个都有自己独立的 ENI。生产环境通常会添加 HTTPS 监听器并配置 ACM 证书,但在初始调试阶段 HTTP 也能正常工作。
ECS 服务与自动扩展
resource "aws_ecs_service" "demo_laravel_web_service" {
name = "demo-laravel-web-service"
cluster = aws_ecs_cluster.demo_laravel_cluster.id
task_definition = aws_ecs_task_definition.demo_laravel_web_task.arn
desired_count = 1
launch_type = "FARGATE"
network_configuration {
subnets = [
aws_subnet.demo_private_a.id,
aws_subnet.demo_private_b.id,
]
security_groups = [aws_security_group.demo_ecs_sg.id]
assign_public_ip = false
}
load_balancer {
target_group_arn = aws_lb_target_group.demo_laravel_tg.arn
container_name = "demo-laravel-web"
container_port = 80
}
depends_on = [aws_lb_listener.demo_laravel_listener]
tags = { Name = "demo-laravel-web-service" }
}
resource "aws_appautoscaling_target" "demo_laravel_web_scaling" {
max_capacity = 4
min_capacity = 1
resource_id = "service/\${aws_ecs_cluster.demo_laravel_cluster.name}/\${aws_ecs_service.demo_laravel_web_service.name}"
scalable_dimension = "ecs:service:DesiredCount"
service_namespace = "ecs"
}
resource "aws_appautoscaling_policy" "demo_laravel_web_cpu_policy" {
name = "demo-laravel-web-cpu-scaling"
policy_type = "TargetTrackingScaling"
resource_id = aws_appautoscaling_target.demo_laravel_web_scaling.resource_id
scalable_dimension = aws_appautoscaling_target.demo_laravel_web_scaling.scalable_dimension
service_namespace = aws_appautoscaling_target.demo_laravel_web_scaling.service_namespace
target_tracking_scaling_policy_configuration {
predefined_metric_specification {
predefined_metric_type = "ECSServiceAverageCPUUtilization"
}
target_value = 70.0
}
}初始部署从 1 个任务开始,当平均 CPU 超过 70% 时可扩展到 4 个任务。首次部署需要几分钟是正常的。Fargate 必须拉取镜像、启动容器、通过健康检查后,服务才会标记为稳定。我曾遇到过冷启动的 Aurora 集群导致首次部署耗时 5 分钟的情况。之后由于 Fargate 会缓存镜像层,部署速度会明显加快。
Fargate 上的队列 Worker
这部分是让我真正认可 Fargate 的关键。相比 Lambda 每个调用只处理一条 SQS 消息并受限于 15 分钟超时,Fargate Worker 运行 php artisan queue:work 作为长驻进程,可以连续处理任务数小时而不受影响。
SQS 队列与死信队列
resource "aws_sqs_queue" "demo_laravel_dlq" {
name = "demo_laravel_dlq"
message_retention_seconds = 1209600
tags = { Name = "demo-laravel-dlq" }
}
resource "aws_sqs_queue" "demo_laravel_queue" {
name = "demo_laravel_queue"
visibility_timeout_seconds = 900
message_retention_seconds = 1209600
redrive_policy = jsonencode({
deadLetterTargetArn = aws_sqs_queue.demo_laravel_dlq.arn
maxReceiveCount = 3
})
tags = { Name = "demo-laravel-queue" }
}这里的可见性超时设为 900 秒,即 15 分钟。使用 Fargate 的核心目的就是处理超过 Lambda 限制的长时间任务。如果一个任务需要 12 分钟完成,但可见性超时只有 2 分钟,SQS 会认为消息未被处理并将其发送给另一个 Worker,而第一个 Worker 仍在运行。这会导致重复处理和难以追踪的 bug。
Worker 任务定义与服务
resource "aws_ecs_task_definition" "demo_laravel_worker_task" {
family = "demo-laravel-worker"
network_mode = "awsvpc"
requires_compatibilities = ["FARGATE"]
cpu = "512"
memory = "1024"
execution_role_arn = aws_iam_role.demo_ecs_execution_role.arn
task_role_arn = aws_iam_role.demo_ecs_task_role.arn
runtime_platform {
operating_system_family = "LINUX"
cpu_architecture = "ARM64"
}
container_definitions = jsonencode([
{
name = "demo-laravel-worker"
image = "${aws_ecr_repository.demo_laravel_ecr.repository_url}:latest"
essential = true
command = ["php", "artisan", "queue:work", "sqs", "--sleep=3", "--tries=3", "--max-time=3600"]
environment = [
{ name = "APP_ENV", value = "production" },
{ name = "APP_KEY", value = var.app_key },
{ name = "DB_CONNECTION", value = "pgsql" },
{ name = "DB_HOST", value = aws_rds_cluster.demo_laravel_db.endpoint },
{ name = "DB_PORT", value = "5432" },
{ name = "DB_DATABASE", value = "demo_laravel" },
{ name = "DB_USERNAME", value = "demo_admin" },
{ name = "DB_PASSWORD", value = var.db_password },
{ name = "REDIS_HOST", value = aws_elasticache_serverless_cache.demo_laravel_cache.endpoint[0].address },
{ name = "REDIS_PORT", value = "6379" },
{ name = "CACHE_STORE", value = "redis" },
{ name = "LOG_CHANNEL", value = "stderr" },
{ name = "QUEUE_CONNECTION", value = "sqs" },
{ name = "SQS_QUEUE", value = aws_sqs_queue.demo_laravel_queue.url },
]
logConfiguration = {
logDriver = "awslogs"
options = {
"awslogs-group" = "/ecs/demo-laravel-worker"
"awslogs-region" = var.aws_region
"awslogs-stream-prefix" = "worker"
}
}
}
])
tags = { Name = "demo-laravel-worker-task" }
}
resource "aws_ecs_service" "demo_laravel_worker_service" {
name = "demo-laravel-worker-service"
cluster = aws_ecs_cluster.demo_laravel_cluster.id
task_definition = aws_ecs_task_definition.demo_laravel_worker_task.arn
desired_count = 0
launch_type = "FARGATE"
network_configuration {
subnets = [
aws_subnet.demo_private_a.id,
aws_subnet.demo_private_b.id,
]
security_groups = [aws_security_group.demo_ecs_sg.id]
assign_public_ip = false
}
tags = { Name = "demo-laravel-worker-service" }
}注意 desired_count = 0。Worker 从零开始,根据队列深度动态扩展。没有任务需要处理时没必要付费运行容器。
通过 CloudWatch 告警实现零扩展
resource "aws_appautoscaling_target" "demo_laravel_worker_scaling" {
max_capacity = 5
min_capacity = 0
resource_id = "service/\${aws_ecs_cluster.demo_laravel_cluster.name}/\${aws_ecs_service.demo_laravel_worker_service.name}"
scalable_dimension = "ecs:service:DesiredCount"
service_namespace = "ecs"
}
resource "aws_cloudwatch_metric_alarm" "demo_queue_depth_high" {
alarm_name = "demo-queue-depth-high"
comparison_operator = "GreaterThanThreshold"
evaluation_periods = 1
metric_name = "ApproximateNumberOfMessagesVisible"
namespace = "AWS/SQS"
period = 60
statistic = "Maximum"
threshold = 10
alarm_description = "队列深度超过 10 时扩展 Fargate Worker"
dimensions = {
QueueName = aws_sqs_queue.demo_laravel_queue.name
}
alarm_actions = [aws_appautoscaling_policy.demo_worker_scale_out.arn]
}
resource "aws_cloudwatch_metric_alarm" "demo_queue_depth_low" {
alarm_name = "demo-queue-depth-low"
comparison_operator = "LessThanThreshold"
evaluation_periods = 3
metric_name = "ApproximateNumberOfMessagesVisible"
namespace = "AWS/SQS"
period = 60
statistic = "Maximum"
threshold = 2
alarm_description = "队列接近空时收缩 Fargate Worker"
dimensions = {
QueueName = aws_sqs_queue.demo_laravel_queue.name
}
alarm_actions = [aws_appautoscaling_policy.demo_worker_scale_in.arn]
}
resource "aws_appautoscaling_policy" "demo_worker_scale_out" {
name = "demo-worker-scale-out"
resource_id = aws_appautoscaling_target.demo_laravel_worker_scaling.resource_id
scalable_dimension = aws_appautoscaling_target.demo_laravel_worker_scaling.scalable_dimension
service_namespace = aws_appautoscaling_target.demo_laravel_worker_scaling.service_namespace
policy_type = "StepScaling"
step_scaling_policy_configuration {
adjustment_type = "ChangeInCapacity"
cooldown = 120
metric_aggregation_type = "Maximum"
step_adjustment {
scaling_adjustment = 2
metric_interval_lower_bound = 0
}
}
}
resource "aws_appautoscaling_policy" "demo_worker_scale_in" {
name = "demo-worker-scale-in"
resource_id = aws_appautoscaling_target.demo_laravel_worker_scaling.resource_id
scalable_dimension = aws_appautoscaling_target.demo_laravel_worker_scaling.scalable_dimension
service_namespace = aws_appautoscaling_target.demo_laravel_worker_scaling.service_namespace
policy_type = "StepScaling"
step_scaling_policy_configuration {
adjustment_type = "ChangeInCapacity"
cooldown = 300
metric_aggregation_type = "Maximum"
step_adjustment {
scaling_adjustment = -1
metric_interval_upper_bound = 0
}
}
}当队列中的消息超过 10 条时,告警触发,ECS 启动 2 个额外的 Worker。当队列消息数连续 3 分钟低于 2 条时,逐步收缩。收缩冷却时间故意设为 5 分钟,避免出现令人恼火的上下反复震荡。
值得对比一下 Lambda 的处理方式。每次调用 Lambda 都处理一条消息,在突发流量时能快速扩展到数百个并行执行,性能很强。代价是每次调用都有 15 分钟的时间限制。Fargate Worker 持续运行同一个进程,处理任务的时间完全由任务本身决定。我个人倾向于对突发性短任务使用 Lambda,对持续性重任务使用 Fargate。零扩展有一个注意事项:当队列空闲一段时间后,第一个到达的任务需要等待 30 到 60 秒才能启动 Worker。如果这对你很重要,可以设置 min_capacity = 1。
App Runner:更简洁的替代方案
如果你读完 Fargate 部分觉得「就为了运行一个 Web 应用要写这么多 Terraform」,我理解你的感受。App Runner 丢弃了大部分复杂性。没有 ALB、没有目标组、没有 ECS 集群、没有服务定义。你只需要提供一个容器镜像,剩下的由它处理。
ECR 访问的 IAM 角色
App Runner 需要权限从私有 ECR 仓库拉取镜像:
resource "aws_iam_role" "demo_apprunner_ecr_role" {
name = "demo-apprunner-ecr-role"
assume_role_policy = jsonencode({
Version = "2012-10-17"
Statement = [{
Action = "sts:AssumeRole"
Effect = "Allow"
Principal = {
Service = "build.apprunner.amazonaws.com"
}
}]
})
tags = { Name = "demo-apprunner-ecr-role" }
}
resource "aws_iam_role_policy_attachment" "demo_apprunner_ecr_policy" {
role = aws_iam_role.demo_apprunner_ecr_role.name
policy_arn = "arn:aws:iam::aws:policy/service-role/AWSAppRunnerServicePolicyForECRAccess"
}App Runner 服务
resource "aws_apprunner_service" "demo_laravel_apprunner" {
service_name = "demo-laravel-apprunner"
source_configuration {
authentication_configuration {
access_role_arn = aws_iam_role.demo_apprunner_ecr_role.arn
}
image_repository {
image_identifier = "${aws_ecr_repository.demo_laravel_ecr.repository_url}:latest"
image_repository_type = "ECR"
image_configuration {
port = "80"
runtime_environment_variables = {
APP_ENV = "production"
APP_KEY = var.app_key
DB_CONNECTION = "pgsql"
DB_HOST = aws_rds_cluster.demo_laravel_db.endpoint
DB_PORT = "5432"
DB_DATABASE = "demo_laravel"
DB_USERNAME = "demo_admin"
DB_PASSWORD = var.db_password
REDIS_HOST = aws_elasticache_serverless_cache.demo_laravel_cache.endpoint[0].address
REDIS_PORT = "6379"
CACHE_STORE = "redis"
SESSION_DRIVER = "redis"
LOG_CHANNEL = "stderr"
FILESYSTEM_DISK = "s3"
AWS_BUCKET = aws_s3_bucket.demo_laravel_uploads.id
}
}
}
auto_deployments_enabled = true
}
instance_configuration {
cpu = "1 vCPU"
memory = "2 GB"
}
health_check_configuration {
path = "/health"
protocol = "HTTP"
}
tags = { Name = "demo-laravel-apprunner" }
}就这么简单。对比 Fargate 的配置,后者需要集群、任务定义、ALB、目标组、监听器、服务,才能处理第一个请求。App Runner 完全跳过了这些。你获得一个带有托管 TLS 证书的公共 HTTPS URL,自动扩展也是开箱即用。
启用 auto_deployments_enabled = true 后,向 ECR 推送新镜像会自动触发新部署。默认零停机,无需额外配置。
当然也有权衡。App Runner 没有原生 SQS 集成,所以不支持这种方式的队列 Worker。你需要用独立的 Lambda 或 Fargate 服务处理后台任务。VPC Connectors 虽然可以访问私有网络,但一旦添加就会让配置明显复杂化,也会增加延迟。资源分配也不够灵活。
说说我的实际选择:内部工具、小项目和快速部署比调优基础设施更重要的场景,我用 App Runner。对于需要 SQS Worker、复杂网络或严格成本控制的项目,我选 Fargate,因为需要那些控制能力。我曾经有一个项目,Web 层用 App Runner,队列 Worker 用 Fargate。这个组合听起来奇怪,但效果出乎意料地好。App Runner 处理简单的 HTTP 流量,Fargate 承担繁重的后台工作。
成本对比
让我列一下几种方案的实际数字。假设一个 Laravel 应用每月处理约 10 万请求,中等强度的后台任务处理。
先说 EC2,因为它最容易理解。一个 t3.medium 实例本身约 30 美元/月。加上 RDS Postgres 的 15 到 25 美元和 ElastiCache 的 12 到 15 美元,总计约 57 到 70 美元。这个账单在中午高峰期和凌晨 3 点空闲时看起来完全一样。确实可预测,但你是在为全天候的峰值容量付费。
Lambda 方案改变了计算方式。10 万请求的 Lambda 计算成本几乎为零。真正的开销是 Aurora Serverless v2,起步价约 43 美元/月,以及 NAT Gateway,如果函数需要访问互联网的话约 32 美元。如果去掉 NAT Gateway,改用第三方 Postgres 提供商而不是 Aurora,总成本可以降到 10 到 15 美元。但如果用完整的 AWS 技术栈——Aurora 加 NAT Gateway——总费用达到 80 到 85 美元。实际上在这个流量级别比 EC2 还贵,这常常让人们感到意外。好处是空闲时真正实现零扩展,流量激增时自动扩展,无需人工干预。
Fargate 有自己的成本曲线,在低流量时最贵。一个持续运行的 Web 任务,0.5 vCPU 和 1GB 内存,ARM64 架构,约 15 美元/月。ALB 额外加约 16 美元的基础费用,还有少量按请求收费。加上 Aurora、ElastiCache 和 NAT Gateway,总计约 105 到 115 美元。这个数字在低流量时确实让人肉疼。但按任务计费非常可预测,对于那些完全无法放入 Lambda 约束的工作负载,这个溢价换来了真正的灵活性。Worker 任务可以收缩到零,有助于控制后台处理成本。
App Runner 计费方式不同。只在服务处理请求时按 vCPU 小时和 GB 小时计费,暂停的实例收取少量费用。10 万请求时,计算部分约 10 到 20 美元,取决于响应时间。但 Aurora、ElastiCache 和可能的 VPC Connector 仍然适用。总计约 70 到 90 美元,介于 Lambda 和 Fargate 之间。
有一点无论选择哪种方案(纯 EC2 除外)都容易被忽视:NAT Gateway。每月 32 美元,它最终成为所谓「无服务器」账单中最大的一笔。仍然让我每次看到它都感到不快。如果你的应用不需要从 VPC 内部调用外部 API,或者可以用 VPC 端点路由那些调用,就去掉 NAT Gateway,把这笔钱省下来。
四种方案的选择最终取决于你的约束。我都在生产环境用过,没有哪种是绝对正确的。简单和可预测就选 EC2。负载符合 15 分钟限制且想要真正的零扩展经济性就选 Lambda。需要持久性、长时间任务或精细网络控制就选 Fargate。想要完全跳过基础设施直接部署就选 App Runner。
